Como ya saben, hace unos días terminó la discusión, e idas y venidas, acerca del grupo de trabajo de derechos humanos del Congreso, presidido por la congresista fujimorista Martha Chavez (@MarthaChavezK36).
La discusión degeneró tanto que llegó al tuiter. La congresista Martha Chavez anunciaba en tuiter sus planes de trabajo dentro de la comisión y respondía a uno que otro insulto tuitero. Era notable la cantidad de tuits emitidos por la congresista. Pero, fueron muchos tuits? pocos? en qué horas acostumbra tuitar la congresista?
Usando herramientas de Linux, Python y unas cuantas librerías «open source» podemos analizar el comportamiento tuitero de Martha Chavez.
Descargué del tuiter los 3200 tuits más recientes de la congresista. Para eso usé un cliente de tuiter usable desde la consola Linux.
t timeline -c -n 3200 MarthaChavezK36 > MarthaChavezK36.csv
Aquí ven parte de los tuits descargados (click para ampliar).

Hice un gráfico del número de tuits por día, usando Python.

timeline de la congresista Martha Chavez
Este timeline comienza el 24 de julio. Vemos que tuvo bastante actividad el 28 de Julio, mediados de Septiembre (cuando se discutía sobre la unión civil de parejas del mismo sexo), primera y segunda semana de Octubre (en esa época se tuiteaba sobre la renuncia de Fujimori por fax), primera semana de Noviembre (cuando se armó el chongo de su elección como coordinadora del grupo de trabajo sobre derechos humanos).
Parece que su destitución del grupo de DDHH no hizo que Martha Chavez tuitee tanto como cuando se hablaba de la unión civil (muy revelador!).
Pero supongo que Martha Chavez tuitea en sus horas libres, cuando ya terminó sus horas de trabajo en el congreso, además de los fines de semana.
Podemos ver esto si usamos sus tuits para generar un «punchcard»:
python analizar_tuits.py MarthaChavezK36.csv | python punchcard.py -f punchcard_Martha_Chavez.png

Esto es alucinante! La congresista tuitea todos los días de la semana. Tuitea a forro entre las 8 y 10 de la mañana (ni bien llega al Congreso?). Tuitea con mayor fuerza los días Viernes. El menor número de tuits a la 1:00pm hace suponer que a esa hora almuerza. Sábados y Domingos, no descansa, tuitea tanto como los días lunes. Y parece que se va a dormir a la 1:00 am. Al parecer duerme menos de 8 horas (eso no es saludable congresista!).
Este nivel de tuits emitidos por Martha Chavez es muy alto? muy bajo? Podemos hacer una comparación con un tuitero consumado, neto y nato. Comparemos con el Útero de Marita:
Este es el punchcard del utero.pe.

Vemos que, al parecer, el útero.pe tuitea menos que la congresista. Uterope tuitea muy poco los viernes, sábados y domingos (a excepción de las 9:00pm cuando tuitea con furia, debe ser que a esa hora pasan los noticieros dominicales). Qué hace el uterope los viernes y fines de semanas que no tuitea? Debe tener buena vida. También tuitea bastante los jueves.
Aqui les dejo el código necesario para hacer este tipo de análisis (?) con cualquier tuitero. Pero fíjense que el tuitero no ande borrando sus tuits ni use tuits programados ya que malograría el «análisis».
Sección geek
Código para producir el gráfico timeline y producir las fechas en formato unix, necesarias para dibujar el punchcard. El programa que hace el punchard lo saqué de aquí: https://github.com/aaronjorbin/punchcard.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| #! /usr/bin/env python | |
| # -*- coding: utf-8 -*- | |
| import sys | |
| import codecs | |
| import re | |
| import datetime | |
| import time | |
| from itertools import groupby | |
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| import brewer2mpl | |
| f = codecs.open(sys.argv[1].strip(), "r", "utf-8") | |
| datos = f.readlines() | |
| f.close() | |
| timestamps = [] | |
| counting = [] | |
| x = [] | |
| for line in datos: | |
| line = line.strip() | |
| if re.search("^[0-9]{6,},", line): | |
| line = line.split(",") | |
| fecha = line[1] | |
| unix_time = time.mktime(datetime.datetime.strptime(fecha, "%Y-%m-%d %H:%M:%S +%f").timetuple()) | |
| # correct for local time Lima -5 hours | |
| unix_time -= 60*60*5 | |
| print unix_time | |
| fecha = fecha.split(" ")[0] | |
| my_time = datetime.datetime.strptime(fecha, "%Y-%m-%d") | |
| if my_time not in timestamps: | |
| timestamps.append(my_time) | |
| counting.append(fecha) | |
| if fecha not in x: | |
| x.append(fecha) | |
| # de reversa | |
| timestamp = timestamps[::-1] | |
| y_axis = [len(list(group)) for key, group in groupby(counting)] | |
| # queremos color | |
| set2 = brewer2mpl.get_map('Set2', 'qualitative', 8).mpl_colors | |
| color = set2[0] | |
| fig, ax = plt.subplots(1) | |
| plt.plot(timestamps, y_axis, color=color) | |
| plt.xticks(rotation="45") | |
| plt.ylabel(u"Número de tuits por día") | |
| plt.title(u'Actividad tuitera de Martha Chavez: timeline') | |
| plt.tight_layout() | |
| plt.savefig("timeline" + sys.argv[1].strip() + ".png") | |
| sys.exit() |


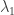 , el promedio de delitos después del punto de quiebre pueder ser la variable
, el promedio de delitos después del punto de quiebre pueder ser la variable 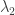 , y el año en que ocurrió el punto de quiebre puede ser la variable tau.
, y el año en que ocurrió el punto de quiebre puede ser la variable tau. y tau).
y tau).

