Hace un par de semanas, el portal Wikileaks publicó el documento secreto correspondiente al borrador de las negociaciones del capítulo de propiedad intelectual del TPP (Trans-Pacific Partnership).
Se supone que este tratado está apunto de ser firmado por el Perú antes de fin de año y gracias a Wikileaks recién podemos darnos cuenta de lo que realmente se ha estado negociando a puerta cerrada.
El documento filtrado al público tiene 96 páginas (si se bajan el PDF) y está disponible aquí. A primera vista se pueden ver los temas que se han discutido y la manera de cómo ha votado cada país. Algunas propuestas parecen provenir de ciertos países mientras que otros votan a favor o se oponen (ver figura 1).
Figura 1. Algunos países votan a favor, otros se oponen.
Podemos dar una lectura a todo el PDF para enterarnos «cómo es la cosa». Pero, siendo este un blog nerd, podemos hacer un «data-mining» rudimentario para rápidamente poder averiguar algunos detalles:
Cuántas veces Perú vota como país de manera opuesta a Estados Unidos?
Cuántas veces Perú vota igual que Estados Unidos?
Podemos averiguar como vota algún país vecino? digamos Chile, vota de manera diferente a Perú?
Chile se opone o vota de manera similar que Estados Unidos?
En qué puntos específicos hay discrepancias en las votaciones
Podría ponerme a contar la votaciones una por una pero me iba a demorar una enternidad. Entonces escribí un script in Python para hacer este data-mining (script completo en la sección geek al final de este post).
Lo bueno es que Wikileaks publicó el documento como PDF conteniendo texto (no como imágenes). Entonces, es bien fácil convertir el PDF a TXT y proceder con el minado de datos.
Si encuentra una línea que contenga la palabra Article se pone alerta y se fija si hay alguna línea con las iniciales de los países PE, CL, US (osea Perú, Chile y Estados Unidos).
La línea de texto que indica la votación tiene un patrón consistente: paísesoppose/proposemás países.
Entonces el script divide la lista de países en dos bandos, los que están a la derecha e izquierda de las palabras clave oppose/propose
Una vez divididos los bandos, solo es cuestión de contar cuántas veces se repiten las iniciales y llevar la cuenta el bando.
Estos son los resultados:
Conteo de votos de PE versus US
propose_together 26
oppose_together 6
oppose_each_other 23
---------------------
Conteo de votos de PE versus CL
propose_together 36
oppose_together 22
oppose_each_other 8
---------------------
Conteo de votos de US versus CL
propose_together 16
oppose_together 2
oppose_each_other 32
Se supone que ambos países, Perú y Chile, tenían la intención hacer propuestas alternativas a las que figuran en el TPP (ver aquí y aquí).
Pero al parecer, esto puede haber quedado en intenciones, al menos viendo la manera cómo ha estado votando Perú.
Perú ha votado igualito que Estados Unidos 32 veces y se ha opuesto (votado diferente) sólo 23 veces. Mientras que Chile ha votado igual que EEUU solo 18 veces y se ha opuesto 32 veces.
Parece que Chile se opone mucho a las propuestas apoyadas por EEUU mientras que Perú vota en tándem. Mi script me dice que:
Chile se opone a US y PE 9 veces
y se opone en estos artículos del TPP:
* Article QQ.C.2: {Collective and Certification Marks}
[US/PE/MX41/SG propose; AU/NZ/ VN/BN/MY/CL/CA oppose: 2. Pursuant to
* Article QQ.D.11: [CL/SG/BN/VN/MX propose82; AU/PE/US/NZ/CA/JP oppose:
* Article QQ.D.12: {Homonymous Geographical Indications}
[NZ/CL/VN/MY/BN/SG/MX propose84; PE/US/AU oppose: 1. Each Party may
[CL propose; AU/US/PE/NZ/VN/SG/MY/BN/MX/CA/JP oppose: 2. The Parties
[CL/SG/BN/MX propose; AU/PE/US/NZ/CA/JP oppose: Annex […] Lists of
* Article QQ.E.9: [US/PE/AU propose; 101 CL/VN/MY/BN/NZ/CA/SG/MX oppose:
* Article QQ.H.7: {Criminal Procedures and Remedies / Criminal Enforcement}
2. [US/AU/SG/PE propose; CL/VN/MY/NZ/CA/BN/MX oppose: Willful
* Article QQ.I.1:267 {Internet Service Provider Liability}
280 [US/PE/SG/AU propose; CL/NZ/VN oppose: A Party may request consultations with the other Parties to
Ahora que tenemos una idea a ojo de buen cubero cómo van las votaciones de Perú, Chile y EEUU, además de los temas potencialmente picantes. Podemos leer mejor el documento filtrado por Wikileaks.
** Spoiler ** (Uno de esos temas tiene que ver con la denominación de origen del Pisco. Chile propone, Perú y EEUU se oponen).
PD. este post se inció a sugerencia de un tuitero amixer.
Sección geek
El script corre de la siguiente manera:
python leeme_votaciones.py texto.txt
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Como ya saben, hace unos días terminó la discusión, e idas y venidas, acerca del grupo de trabajo de derechos humanos del Congreso, presidido por la congresista fujimorista Martha Chavez (@MarthaChavezK36).
La discusión degeneró tanto que llegó al tuiter. La congresista Martha Chavez anunciaba en tuiter sus planes de trabajo dentro de la comisión y respondía a uno que otro insulto tuitero. Era notable la cantidad de tuits emitidos por la congresista. Pero, fueron muchos tuits? pocos? en qué horas acostumbra tuitar la congresista?
Usando herramientas de Linux, Python y unas cuantas librerías «open source» podemos analizar el comportamiento tuitero de Martha Chavez.
Descargué del tuiter los 3200 tuits más recientes de la congresista. Para eso usé un cliente de tuiter usable desde la consola Linux.
t timeline -c -n 3200 MarthaChavezK36 > MarthaChavezK36.csv
Aquí ven parte de los tuits descargados (click para ampliar).
Hice un gráfico del número de tuits por día, usando Python.
timeline de la congresista Martha Chavez
Este timeline comienza el 24 de julio. Vemos que tuvo bastante actividad el 28 de Julio, mediados de Septiembre (cuando se discutía sobre la unión civil de parejas del mismo sexo), primera y segunda semana de Octubre (en esa época se tuiteaba sobre la renuncia de Fujimori por fax), primera semana de Noviembre (cuando se armó el chongo de su elección como coordinadora del grupo de trabajo sobre derechos humanos).
Parece que su destitución del grupo de DDHH no hizo que Martha Chavez tuitee tanto como cuando se hablaba de la unión civil (muy revelador!).
Pero supongo que Martha Chavez tuitea en sus horas libres, cuando ya terminó sus horas de trabajo en el congreso, además de los fines de semana.
Podemos ver esto si usamos sus tuits para generar un «punchcard»:
Esto es alucinante! La congresista tuitea todos los días de la semana. Tuitea a forro entre las 8 y 10 de la mañana (ni bien llega al Congreso?). Tuitea con mayor fuerza los días Viernes. El menor número de tuits a la 1:00pm hace suponer que a esa hora almuerza. Sábados y Domingos, no descansa, tuitea tanto como los días lunes. Y parece que se va a dormir a la 1:00 am. Al parecer duerme menos de 8 horas (eso no es saludable congresista!).
Este nivel de tuits emitidos por Martha Chavez es muy alto? muy bajo? Podemos hacer una comparación con un tuitero consumado, neto y nato. Comparemos con el Útero de Marita:
Vemos que, al parecer, el útero.pe tuitea menos que la congresista. Uterope tuitea muy poco los viernes, sábados y domingos (a excepción de las 9:00pm cuando tuitea con furia, debe ser que a esa hora pasan los noticieros dominicales). Qué hace el uterope los viernes y fines de semanas que no tuitea? Debe tener buena vida. También tuitea bastante los jueves.
Aqui les dejo el código necesario para hacer este tipo de análisis (?) con cualquier tuitero. Pero fíjense que el tuitero no ande borrando sus tuits ni use tuits programados ya que malograría el «análisis».
Sección geek
Código para producir el gráfico timeline y producir las fechas en formato unix, necesarias para dibujar el punchcard. El programa que hace el punchard lo saqué de aquí: https://github.com/aaronjorbin/punchcard.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Ministros y ex-primer ministros de este gobierno coinciden en pensar que la inseguridad ciudadana es una percepción, ilusión de la gente, producto de estados mentales histéricos y que no hay que quejarse tanto.
Figura 2. Regresión lineal de número total de delitos versus año.
La regresión lineal (y el gráfico) nos dice que conforme pasan los años ha aumentado la delincuencia (R2 = 0.67) de manera significativa (p-value = 0.008).
Se observa que entre los años 2008 y 2011 ocurrió un punto de quiebre y la delicuencia aumentó, pero no podemos apuntar con precisión en qué año comenzó esta racha de mayor número de delitos. Además que los datos no se ajustan muy bien a la línea de tendencia. Pareciera que el aumento de delitos no es lineal, parece ser exponencial! Esta incertidumbre es parte de las limitaciones de las estadísticas que estoy usando, esta corriente llamada estadísticas frecuentistas.
Estadísticas bayesianas
Pero afortunadamente existen las estadísticas bayesianas que nos pueden dar algo más de información respecto a este tema.
Estas estadísticas nos pueden ayudar a estimar en qué año aumentó la delincuencia. Por ejemplo, el promedio de delitos anuales antes de este incremento puede ser considerado como la variable , el promedio de delitos después del punto de quiebre pueder ser la variable , y el año en que ocurrió el punto de quiebre puede ser la variable tau.
Podemos estimar el rango de valores más probables que puede tener cada variable si es que usamos simulaciones de números aleatorios.
[Paréntesis]
Los estadísticos bayesianos conocen la probabilidad más alta de estos valores como probabilidad posterior. Por ejemplo, cuando tú amig@ lector(a) recibes un email (digamos de Gmail), la empresa Google tiene un software que aplica estadísticas bayesianas al contenido del mensaje. Lo que hace es buscar palabras clave que indiquen que el email recibido es spam. La probabilidad inicial que un mensaje sea Spam puede ser 0.5 (osea 50%), pero si el contenido tiene las palabras «viagra», «penis», «enlargement». Existirá una mayor probabilidad que este correo es spam, (a esta probabilidad se le llama probabilidad posterior ya que se obtiene luego de examinar la evidencia), y el software de Google lo enviará directamente a la carpeta Junk. Por eso las estadísticas bayesianas son importantes, y además las usas a diario sin darte cuenta. [/Paréntesis]
Volviendo a nuestro problema, necesitamos ver cuáles son las probabilidades posteriores de nuestros datos de número de delitos a nivel nacional. Felizmente, el lenguaje de programación Python tiene una librería muy chévere para hacer estadísticas bayesianas. Es el paquete pymc. Entonces solo es cuestion de simular muchas veces los valores de números totales de delito antes y después del incremento, y el año de incremento en la tasa delincuencial (osea y tau).
Realicé una simulación de 50 mil generaciones usando una cadena Markov Monte Carlo, descarté las primeras 10 mil generaciones y dibujé los resultados:
Vemos que hay una diferencia notable entre el total esperado de delitos antes () y después () del incremento (casi 160 mil delitos antes y 230 mil delitos luego del incremento de la delincuencia).
También vemos que es más probable que en el 6to año (osea año 2011) ocurrió la aceleración de la delincuencia en el Perú.
Podemos combinar estas tres variables en un solo gráfico:
Este gráfico muestra los valores esperados de delito antes, después y durante la aceleración en el nivel de delicuencia. Vemos que esto ocurrió del año 2010 al 2011.
Ahora, pregunto qué acontecimiento ocurrió entre 2010 y 2011 que fue el causante del aumento de la delicuencia en nuestro país? El que sepa «que levante la mano».
Sección geek
Aquí los datos que he usado:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Auí está el código para hacer la regresión lineal en R:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Aquí el código para hacer el análisis bayesiano (usa Python, pymc, y prettyplotlib):
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
«A person who enjoys exploring the details of programmable systems and stretching their capabilities, as opposed to most users, who prefer to learn only the minimum necessary.»
Algunos creen equivocadamente que hacker = malechor, delincuente. Pero lo cierto es que hay varios tipos de hackers.
Aquel que infringe medidas de seguridad con fines maléficos, también se le conoce como «cracker».
Un miembro de la comunidad Unix de programas de computación libre y «open source», o alguien que usa este principio para desarrollo de software o hardware.
Además individuos considerados como hackers de la subcultura de programadores pueden hacer tareas repititivas de 100 a 1,000 veces más rapido que usuarios que no son hackers (gracias a que usan de técnicas de computación avanzadas).
Para demostrar qué tan mal redactada está la ley ex-beingolea. He decidido hackear las páginas web del Congreso de la República. Y aquí detallo el procedimiento.
Quiero hacer uso de programas informáticos para averiguar cúantos proyectos de ley ha propuesto cada congresista durante este año 2013.
Hay que buscar la página web del congreso que tiene la lista de los proyectos de ley emitidos este año:
Buscar la página con los proyectos de ley.
Listado de proyectos de ley por fecha.
Si vemos el código original HTML de esa página (hacer CTRL-U, si están en Mozilla Firefox) veremos que está compuesta de 4 «frames». Cada «frame» corresponde a una parte de la página. Me interesa el último «frame», el que contiene la lista de links a los proyectos de ley.
Código HTML de la página del congreso
Si hacemos click al último «frame» nos encontramos con esta página:
«Frame» conteniendo la lista de proyectos de ley.
Esta página lista 100 proyectos de ley, y al ver la dirección URL de esta página, nos damos cuenta que basta con cambiar el último parámetro Start=1 por Start=100 para obtener los siguientes 100 proyectos de ley.
Puedo escribir un hack (osea script) que me colecte rápidamente todas las páginas que contienen los links. En lugar de bajarme documento por documento (lo cual me tomaría muuuuucho tiempo), lo puedo hacer al toque si hago uso de las tecnologías de información y comunicación que tanto miedo causa a los congresistas:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Hay 812 proyectos de ley para examinar. Necesitamos descargar cada proyecto de ley y copiar la lista de autores para contar cuántos proyectos ha sido emitido por cada congresista. Obviamente hacer esto manualmente me demoraría una eternidad. Para eso he creado un segundo hack. Es un script in Python que examina cada link, y extrae los nombres de los congresistas que son autores de cada proyecto de ley. Junta todos los nombres y hace un gráfico para poder visualizar los datos (el código de programación está al final de este post).
Bueno, el script estaba demorando mucho, me cansé de esperar y cancelé el programa por lo que no pude colectar toda la info. Pero la idea se entiende no?
Número de proyectos de ley presentado por cada congresista durante el 2013
Hagamos recuento de las veces que he faltado a la ley:
Artículo 3. Atentado a la integridad de datos informáticos
El que, a través de las tecnologias de la información o de la comunicación, introduce,
borra, deteriora, altera, suprime o hace inaccesibles datos informáticos, será reprimido
con pena privativa de libertad
-> Al escribir este post he introducido datos informáticos al servidor de WordPress usando tecnologías de la comunicación.
Articulo 6. Tráfico ilegal de datos
El que, crea, ingresa, o utiliza indebidamente una base de datos sobre una persona natural o jurídica, identificada o identificable, para comercializar; traficar, vender, promover, favorecer o facilitar información relativa a cualquier ámbito de la esfera personal, familiar, patrimonial, laboral, financiera u otro de naturaleza análoga, creando o no perjuicio, será reprimido con pena privativa de libertad no menor de tres ni mayor de cincó años.
-> Al bajarme la lista de proyectos de Ley del Congreso he ingresado a su base de datos para facilitar la información relativa al ámbito laboral de cada congresista sin crear perjuicio (ojo que no es necesario causar perjuicio para ir en contra de la ley).
Artículo 1O. Abuso de mecanismos y dispositivos informáticos
El que fabrica, diseña, desarrolla, vende, facilita, distribuye, importa u obtiene para su utilización, uno o más mecanismos, programas informáticos, dispositivos, contraseñas, códigos de acceso o cualquier otro dato informático, específicamente diseñados para la comisión de los delitos previstos en la presente Ley, o el que ofrece o presta servicio que contribuya a ese propósito, será reprimido con pena privativa de libertad no menor de uno
ni mayor de cuatro años y con treinta a noventa días-multa.
-> En este post publico el programa informático que he fabricado, diseñado y desarrollado con el fin de específicamente incumplir los artículos 3 y 6 de la presente Ley.
Conclusión
He violado la ley de delitos informáticos (ley ex-beingolea) 3 veces
Señores congresistas métanme preso. Quiero cárcel dorada como Antauro y Fujimori. Gracias.
Sección para geeks
Aqui está el código para bajarse los nombres de los congresistas que fueron autores de proyectos de ley durante el 2013:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
El útero de marita está emitiendo informes diarios acerca de los manejos del dinero que realiza APDAYC en nombre de los compositores y escritores de música del Perú.
Marco Sifuentes escribió en Facebook que requiere ayuda para poder asimilar mejor todos los destapes que está posteando en su blog utero.pe (junto con Jonathan Castro).
Con ánimos de ayudar a la causa (#intervenganAPDAYC) me puse a ver la cantidad de dinero que cobraron algunos directivos del APDAYC durante el 2012, por concepto de derechos de autor. En el post uterino «se la llevan facil» aparecen algunos números, pero no se aprecia si esta ganancia es mucho (o poco) en comparación con lo ganado por los asociados de APDAYC que no son miembros del Consejo Directivo.
Intenté hacer un gráfico de lo ganado por los compositores más prolíficos en comparación con el dinero que cobraron los directivos de APDAYC.
Obtuve la lista de directivos de aqui. Y las ganancias de los 250 asociados que tuvieron más regalías durante el 2012 de aqui.
Tuve que bajarme el PDF, convertirlo a texto, y dibujar el gráfico. Como soy bien nerd, para convertir el texto usé comandos de Linux y para dibujar el gráfico usé el lenguaje de programación Python (con su librería gráfica matplotlib).
Aqui está el gráfico, y más abajo el código que tuve que tipear para hacer este «análisis» tan diligente 😉 (hacer click para agrandar la imagen).
Los que más cobraron, APDAYC 2012
Manya, son haaaaaartos los compositores que cobran regalías. Pero son unos pocos quien se llevan harta plata, y son muchos los que cobran poquito (se lleva 3 mil soles al año el que está en puesto 250).
Debemos alegrarnos por los miembros del Consejo Directivo de APDAYC que son afortunados en estar entre los que más regalías se llevaron durante el 2012 (por ejemplo José Escajadillo, Armando Massé y Julio Andrade, entre otros).
[Actualización 6 de Octubre 2013]
Un tuitero/bloguero influyente me sugirió averiguar si hay un patrón de las ganancias recibidas por los socios que tienen mayor poder de decisión en APDAYC. Osea ver si los que cortan en jamón en APDAYC ganan más o ganan menos en comparación con los socios que tienen menor voto en los manejos de la Sociedad Colectiva APDAYC.
Se supone que en una democracia cada persona es igual a un voto, pero en APDAYC eso no es así. Entonces los que tienen mayor poder de decisión del rumbo de APDAYC, los que parten y reparten son principalmente ese grupo de socios principales, vitalicios y activos.
Cuanto reciben de regalías los que cortan el jamón en APDAYC?
Estuve mirando otra vez los datos y me di cuenta que estos socios privilegiados son casi la mitad (138 socios, o el 55%) pero se llevan la mayoría de plata recaudada en APDAYC. El 84% del dinero cobrado por regalías durante el 2012 (7 millones de soles) se lo llevaron este grupo de socios con voto privilegiado. Mientras que la otra mitad de socios le corresponde poco más de 1 millon (16% del total).
Resulta interesante que los que cortan el jamón en APDAYC se lleven el 84% del dinero (a pesar de ser la mitad de socios con derecho a voto).
Bueno dicen que el que parte y reparte se lleva la mayor parte?
Aqui les dejo el gráfico para digerir mejor los datos (al final de este post está todo el código usado para los análisis).
La mitad de socios tiene voto privilegiado, cada voto vale de 3 a 5 veces que los votos de la otra mitad. Es curioso que además se lleven la mayor tajada de las regalías recaudadas por APDAYC.
[Actualización 7 Oct 2013]
Pero qué porcentaje de TODAS las regalías recibe este grupo de socios?
Según el útero de marita«APDAYC tiene más de 8 mil afiliados, pero sólo 248 tienen derecho a voto en la Asamblea General».
Supongamos que APDAYC tiene 8 mil socios, entonces entre ellos repartieron 29 millones de soles durante el 2012.
Quiero saber:
Qué porcentaje de estos 8mil son los socios con votos privilegiados (principales, vitalicios y activos).
Qué porcentaje del dinero total se llevan estos socios con voto privilegiado?
Estos son los datos:
Dinero total: 29,197,272 Soles
Número total de socios: 8000
Total socios con voto privilegiado: 138
Dinero recibido por socios principales: 1240,041.19
Dinero recibido por socios vitalicios: 59,347.69
Dinero recibido por socios activos: 5731,717.18
Porcentaje de socios con voto privilegiado: 1.7%
Porcentaje del dinero que se recibe este grupo: 24.08%
Y este es el gráfico resultante:
Porcentaje de ganancias de socios con voto privilegiado, APDAYC 2012
Pues es de esperarse que el 1.7% de socios se lleve la cuarta parte de las regalías. Si vemos otra vez el gráfico de los socios más rendidores, los que más plata reciben, veremos que son los socios principales y activos (con voto multiplicado por 5 y por 3) quienes reciben más regalías.
Los socios principales y activos son los que más regalías cobraron durante el 2012.
Sección para geeks
Aqui el código en la consola de Linux:
# Bajarse la memoria en PDF y extraer las páginas 34, 35 y 36
pdftk Memoria_APDAYC_2012.pdf cat 34-36 output mas_productivos_2012.pdf
# convertir PDF a texto
pdftotext -layout mas_productivos_2012.pdf
# hacer limpieza manual para eliminar texto que no se necesita (joyas y premios)
# extraer nombres y ganancias
cat mas_productivos_2012.txt | sed 's/S\/\.//g' | sed 's/\$//g' | sed 's/\s\+/ /g' | sed -r 's/([A-Z]),/\1/g' | sed 's/,//g' | sed -r 's/(([A-Z]+\s)+)/\1,/g' | sed 's/ ,/,/g' | sed -r 's/^[0-9]+\s[0-9]+\s//g' | sed -r 's/\s*$//g' > tmp_mas_productivos.txt
# dibujar el gráfico usando Python y matplotlib
python mas_productivos.py
Y aqui el código actualizado en el lenguage Python:
# -*- coding: utf-8 -*-
import codecs
import locale
import prettyplotlib as ppl
import numpy as np
from prettyplotlib import plt
locale.setlocale(locale.LC_ALL, 'en_US.UTF-8')
f = codecs.open("output/tmp_socios_principales.txt", encoding="utf-8")
data = f.read()
f.close()
# Esta es la lista de "Socios principales"
data = data.split("\n")
principales = []
vitalicios = []
activos = []
for line in data:
line = line.strip()
if len(line) > 0:
line = line.split(",")
if line[1] == "PRINCIPAL":
principales.append(line[0])
if line[1] == "VITALICIO":
vitalicios.append(line[0])
if line[1] == "ACTIVO":
activos.append(line[0])
# cantidad de regalias por "socios principales"
f = codecs.open("output/tmp_mas_productivos.txt", encoding="utf-8")
data = f.read()
f.close()
data = data.split("\n")
princi_money = float()
vitali_money = float()
activo_money = float()
otros_money = float()
for i in data:
if len(i) > 0:
i = i.split(",")
author = i[0]
money = i[1].split(" ")
money = money[len(money)-1]
if author in principales:
princi_money += float(money)
elif author in vitalicios:
vitali_money += float(money)
elif author in activos:
activo_money += float(money)
else:
otros_money += float(money)
## DO principales + vitalicios
## numero de socios por categoria
numero_socios = [str(len(principales) + len(vitalicios)),
str(250-len(principales)-len(vitalicios))]
print "Socios privilegiados con el voto " + str(len(principales) +
len(vitalicios) + len(activos))
y = [princi_money + vitali_money, activo_money + otros_money]
annotate = [locale.format("%d", y[0], grouping=True) + " S/.",
locale.format("%d", y[1], grouping=True) + " S/."]
width = 0.35
bar_color = ["r", "#66c2a5"]
plt.rc('font', **{'family': 'DejaVu Sans'})
fig, ax = plt.subplots(1, figsize=(8,6))
ind = np.arange(2)
xdata = ind + 0.05 + width
ax.bar(ind, y)
ax.set_xticks(ind + 0.4)
ax.set_xticklabels(["principales y vitalicios\n(" + numero_socios[0] + " socios)",
"otros socios\n(" + numero_socios[1] + " socios)",
],
rotation="horizontal", multialignment="center")
ax.autoscale()
ax.set_title(u'Ganancias de socios principales y vitalicios\n comparados con el resto de socios',
fontdict = {'fontsize':22}
)
y_labels = ["0", "1,000,000", "2,000,000", "3,000,000", "4,000,000",
"5,000,000", "6,000,000", "7,000,000", "8,000,000"]
ax.set_yticklabels(y_labels)
plt.ylabel(u'Regalías en S/.', fontdict={'fontsize':18})
plt.xlabel(u'Beneficiarios', fontdict={'fontsize':22})
ppl.bar(ax, np.arange(len(y)), y, grid="y", annotate=annotate, color=bar_color)
fig.tight_layout()
fig.savefig("output/socios_principales.png")
output = "Plot de socios Principales + Vitalicios guardados en archivo "
output += "``output/socios_principales.png``\n"
print output
## DO principales + vitalicios + activos
## numero de socios por categoria
numero_socios = [str(len(principales) + len(vitalicios) + len(activos)),
str(250-len(principales) - len(vitalicios) - len(activos))]
# Porcentaje de socios principales+vitalicios+activos versus otros
percent_pva = float((len(principales)+len(vitalicios)+len(activos))*100/250)
percent_socios_otros = 100.0 - percent_pva
# Porcentaje de DINERO de socios principales+vitalicios+activos versus otros
y = [princi_money + vitali_money + activo_money, otros_money]
percent_money_pva = int(float(princi_money + vitali_money + activo_money)*100/(y[0] + y[1]))
percent_money_otros = 100 - percent_money_pva
annotate = [locale.format("%d", y[0], grouping=True) +
" S/.",
locale.format("%d", y[1], grouping=True) +
" S/."]
width = 0.35
bar_color = ["r", "#0099FF"]
plt.rc('font', **{'family': 'DejaVu Sans'})
fig, ax = plt.subplots(1, figsize=(9,6))
ind = np.arange(2)
xdata = ind + 0.05 + width
# write percentaje of money to plot
ax.annotate(str(percent_money_pva) +"%\ndel dinero", ha="center", color="w",
size=38, xy=(0.2,1.2), xytext=(0.4, 2500000))
ax.annotate(str(percent_money_otros) +"%\ndel dinero", ha="center", color="w",
size=18, xy=(0.2,1.2), xytext=(1.4, 150000))
ax.bar(ind, y)
ax.set_xticks(ind + 0.4)
ax.set_xticklabels(["principales, vitalicios y activos\n(" +
str(int(percent_pva)) + "% del total)",
"otros socios\n(" +
str(int(percent_socios_otros)) + "% del total)"
],
rotation="horizontal", multialignment="center")
ax.autoscale()
ax.set_title(u'Ganancias de socios principales, vitalicios y activos'
+ '\ncomparados con el resto de socios',
fontdict = {'fontsize':22}
)
y_labels = ["0", "1,000,000", "2,000,000", "3,000,000", "4,000,000",
"5,000,000", "6,000,000", "7,000,000", "8,000,000"]
ax.set_yticklabels(y_labels)
plt.ylabel(u'Regalías en S/.', fontdict={'fontsize':18})
plt.xlabel(u'Beneficiarios', fontdict={'fontsize':22})
ppl.bar(ax, np.arange(len(y)), y, annotate=annotate, color=bar_color)
fig.tight_layout()
fig.savefig("output/socios_principales_vitalicios_activos.png")
output = "Plot de socios Principales + Vitalicios + Activos guardados en archivo "
output += "``output/socios_principales_vitalicios_activos.png``\n"
print output
Código de cuáles miembros del consejo directivo se llevan más regalías
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters







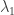 , el promedio de delitos después del punto de quiebre pueder ser la variable
, el promedio de delitos después del punto de quiebre pueder ser la variable 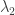 , y el año en que ocurrió el punto de quiebre puede ser la variable tau.
, y el año en que ocurrió el punto de quiebre puede ser la variable tau. y tau).
y tau).










