A modo de prueba he empezado a publicar en el blog El Útero de Marita. Ahora estoy en el dominio http://aniversarioperu.utero.pe/
No se sabe si este movimiento es efímero, y regrese a publicar en este blog. Solo el tiempo lo dirá.
A modo de prueba he empezado a publicar en el blog El Útero de Marita. Ahora estoy en el dominio http://aniversarioperu.utero.pe/
No se sabe si este movimiento es efímero, y regrese a publicar en este blog. Solo el tiempo lo dirá.
Artículo publicado en utero.pe
Esta es la primera entrega de un tema que puede ser de tu interés.
Según la Global Editors Network, el periodismo de datos se puede dividir en varias categorías, las cuales no son necesariamente excluyentes ya que usan métodos y protocolos comunes y tienden a ser complementarias.
Estas son las categorías:
Según Wikipedia, el periodismo investigativo de datos (lo que llamaremos «periodismo de datos» por simplicidad) es un proceso periodístico que se basa en el análisis y filtrado de grandes bases de datos con el propósito de crear una noticia periodística.
Me voy a concentrar en esta categoría ya que exiten varios reportajes de periodismo de datos en esta línea que han ganado concursos internacionales:
Si bien una investigación periodística inicia con un dateo ya sea de un «garganta profunda» o un Edward Snowden, a veces es necesario obtener los datos de manera independiente. A veces los datos son facilitados por el datero pero muchas veces los datos están disponibles en los portales de instituciones estatales, registros públicos, etc.
A veces la obtención de datos es forzosamente lenta. Por ejemplo cuando uno pide datos en la SUNARP. Otras veces los datos se pueden obtener a por montones y rápidamente si se tiene la ayuda de un hacker (un hacker ético, claro está; si no tienes hacker, consíguete un geek). Por ejemplo el Ministerio de Justicia tiene en su web todas las resoluciones ministeriales emitidas en formato PDF. Bajarse cada PDF implicaría hacer una búsqueda en su portal, seleccionar la resolución del día que te quieres bajar y finalmente hacer click en «download». Durante el segundo gobierno aprista se emitieron 2,184 resoluciones y bajar todos estos PDFs manualmente, uno por uno, demoraría una eternidad.

geek promedio
Pero lo bueno es que los archivos están almacenados de manera consistente. El nombre de cada archivo PDF consiste en la fecha en que se emitió la resolución (ddmmyy, osea día, mes y año):
http://spij.minjus.gob.pe/Normas/textos/ddmmyyT.pdfEste trabajo es demasiado fácil para un hacker ético. Solo basta escribir un programita de 9 líneas de código para bajarse TODAS las resoluciones:
| ## Lista de links de las Normas del Ministerio de Justicia del 2006 al 2011 | |
| # Bajar fechas 00-01-06 hasta 39-09-09 | |
| curl -o '#1#2-0#3-0#4.pdf' 'http://spij.minjus.gob.pe/Normas/textos/%5B0-1%5D%5B0-1%5D0%5B1-1%5D0%5B6-6%5DT.pdf' | |
| sleep $[ ( RANDOM % 10 ) + 1]m | |
| # Bajar fechas 00-01-06 hasta 39-09-09 | |
| curl -o '#1#2-0#3-0#4.pdf' 'http://spij.minjus.gob.pe/Normas/textos/%5B0-3%5D%5B0-9%5D0%5B1-9%5D0%5B6-9%5DT.pdf' | |
| sleep $[ ( RANDOM % 10 ) + 1]m | |
| # Bajar fechas 00-01-10 hasta 39-09-11 | |
| curl -o '#1#2-0#3-#4.pdf' 'http://spij.minjus.gob.pe/Normas/textos/%5B0-3%5D%5B0-9%5D0%5B1-9%5D%5B10-11%5DT.pdf' | |
| sleep $[ ( RANDOM % 10 ) + 1]m | |
| # Bajar fechas 00-10-06 hasta 39-12-09 | |
| curl -o '#1#2-1#3-0#4.pdf' 'http://spij.minjus.gob.pe/Normas/textos/%5B0-3%5D%5B0-9%5D1%5B0-2%5D0%5B6-9%5DT.pdf' | |
| sleep $[ ( RANDOM % 10 ) + 1]m | |
| # Bajar fechas 00-10-10 hasta 39-12-11 | |
| curl -o '#1#2-1#3-#4.pdf' 'http://spij.minjus.gob.pe/Normas/textos/%5B0-3%5D%5B0-9%5D1%5B0-2%5D%5B10-11%5DT.pdf' |
Una vez que el programa empieza a correr irá bajando cada PDF, un por uno, ya que el nombre de los archivos se puede constuir usando las fechas de un calendario. Este programa terminará su trabajo en unas cuantas horas sin necesidad que el periodista y/o hacker realicen actividad manual alguna.
Los geeks tienen muchas herramientas open-source disponibles para realizar sus actividades. Una herramienta que se usa mucho para descargar contenido desde las web se conoce como curl. Si se usa correctamente, este programa puede aparentar ser un usuario humano, ya que puede suministar nombre de usuario y contraseña a las páginas que lo requieran, puede lidiar con cookies, usar certificados para autenticación, usar proxies y muchas cosas más. Es algo así como la navaja suiza de los geeks para asuntos de descarga de datos.
Como ves, es muy ventajoso para un periodista de investigación estar asociado a uno o más hackers, o geeks, o nerds. Uno de los aportes principales de los hackers éticos al periodismo de datos es la rapidez. Al aprovechar de sus habilidades tecnológicas es posible acelerar la investigación sobre todo cuando hay que realizar actividades repetitivas. En el mundo digital, las actividades repetitivas deben ser ejecutadas por computadoras, no por humanos. Las computadoras son buenas para ejecutar tareas repetitivas ya que son infinitamente más rápidas que un humano.
Esas tareas repetitivas pueden ser automatizadas y ejecutadas por los hackers y sus computadoras. La labor del periodista es otra, es analizar qué datos son importantes de ser cosechados, qué otro tipo de datos deben ser asociados con el fin de obtener una historia. La labor analítica y de pensamiento crítico debe ser realizada por el periodista. Para esto es de vital importancia la experiencia e intuición de periodista.
Amigo, amiga periodista, si necesitas bajar cientos, miles de PDFs, imágenes o páginas de un sitio web, contáctate con tu geek más cercano. Hay altas probabilidades que el geek pueda usar sus habilidades para bajar lo que necesitas en un santiamén.
Hace un par de semanas, el portal Wikileaks publicó el documento secreto correspondiente al borrador de las negociaciones del capítulo de propiedad intelectual del TPP (Trans-Pacific Partnership).
Ya han habido varias alertas acerca de las implicancias de estas negociaciones (una introducción al tema aquí). Además de ser negociaciones que se realizan de manera secreta, preocupa que esté en riesgo el libre acceso a Internet y el componente de propiedad intelectual que pueda dificultar el acceso a medicamentos.
Se supone que este tratado está apunto de ser firmado por el Perú antes de fin de año y gracias a Wikileaks recién podemos darnos cuenta de lo que realmente se ha estado negociando a puerta cerrada.
El documento filtrado al público tiene 96 páginas (si se bajan el PDF) y está disponible aquí. A primera vista se pueden ver los temas que se han discutido y la manera de cómo ha votado cada país. Algunas propuestas parecen provenir de ciertos países mientras que otros votan a favor o se oponen (ver figura 1).

Figura 1. Algunos países votan a favor, otros se oponen.
Podemos dar una lectura a todo el PDF para enterarnos «cómo es la cosa». Pero, siendo este un blog nerd, podemos hacer un «data-mining» rudimentario para rápidamente poder averiguar algunos detalles:
Podría ponerme a contar la votaciones una por una pero me iba a demorar una enternidad. Entonces escribí un script in Python para hacer este data-mining (script completo en la sección geek al final de este post).
Lo bueno es que Wikileaks publicó el documento como PDF conteniendo texto (no como imágenes). Entonces, es bien fácil convertir el PDF a TXT y proceder con el minado de datos.
pdftotext Wikileaks-secret-TPP-treaty-IP-chapter.pdf texto.txt
Mi script funciona de la siguiente manera:
Estos son los resultados:
Conteo de votos de PE versus US propose_together 26 oppose_together 6 oppose_each_other 23 --------------------- Conteo de votos de PE versus CL propose_together 36 oppose_together 22 oppose_each_other 8 --------------------- Conteo de votos de US versus CL propose_together 16 oppose_together 2 oppose_each_other 32
Se supone que ambos países, Perú y Chile, tenían la intención hacer propuestas alternativas a las que figuran en el TPP (ver aquí y aquí).
Pero al parecer, esto puede haber quedado en intenciones, al menos viendo la manera cómo ha estado votando Perú.
Perú ha votado igualito que Estados Unidos 32 veces y se ha opuesto (votado diferente) sólo 23 veces. Mientras que Chile ha votado igual que EEUU solo 18 veces y se ha opuesto 32 veces.
Parece que Chile se opone mucho a las propuestas apoyadas por EEUU mientras que Perú vota en tándem. Mi script me dice que:
Chile se opone a US y PE 9 veces
y se opone en estos artículos del TPP:
* Article QQ.C.2: {Collective and Certification Marks}
[US/PE/MX41/SG propose; AU/NZ/ VN/BN/MY/CL/CA oppose: 2. Pursuant to
* Article QQ.D.11: [CL/SG/BN/VN/MX propose82; AU/PE/US/NZ/CA/JP oppose:
* Article QQ.D.12: {Homonymous Geographical Indications}
[NZ/CL/VN/MY/BN/SG/MX propose84; PE/US/AU oppose: 1. Each Party may
[CL propose; AU/US/PE/NZ/VN/SG/MY/BN/MX/CA/JP oppose: 2. The Parties
[CL/SG/BN/MX propose; AU/PE/US/NZ/CA/JP oppose: Annex […] Lists of
* Article QQ.E.9: [US/PE/AU propose; 101 CL/VN/MY/BN/NZ/CA/SG/MX oppose:
* Article QQ.H.7: {Criminal Procedures and Remedies / Criminal Enforcement}
2. [US/AU/SG/PE propose; CL/VN/MY/NZ/CA/BN/MX oppose: Willful
* Article QQ.I.1:267 {Internet Service Provider Liability}
280 [US/PE/SG/AU propose; CL/NZ/VN oppose: A Party may request consultations with the other Parties to
Ahora que tenemos una idea a ojo de buen cubero cómo van las votaciones de Perú, Chile y EEUU, además de los temas potencialmente picantes. Podemos leer mejor el documento filtrado por Wikileaks.
** Spoiler ** (Uno de esos temas tiene que ver con la denominación de origen del Pisco. Chile propone, Perú y EEUU se oponen).
PD. este post se inció a sugerencia de un tuitero amixer.
El script corre de la siguiente manera:
python leeme_votaciones.py texto.txt
| import re | |
| import sys | |
| f = open(sys.argv[1].strip(), "r") | |
| lines = f.readlines() | |
| f.close() | |
| def clean_line(line): | |
| propose = "" | |
| oppose = "" | |
| if "propose" in line or "oppose" in line: | |
| try: | |
| propose = re.search("(([A-Z]{2}[0-9]*\/*\s*)+\spropose)", line).groups()[0] | |
| propose = re.sub("[0-9]+", "", propose) | |
| except: | |
| pass | |
| try: | |
| oppose = re.search("(([A-Z]{2}[0-9]*\/*\s*)+\soppose)", line).groups()[0] | |
| oppose = re.sub("[0-9]+", "", oppose) | |
| except: | |
| pass | |
| return [propose, oppose] | |
| def count_countries(pais1, pais2, lines): | |
| propose_together = 0 | |
| oppose_together = 0 | |
| oppose_each_other = 0 | |
| for line in lines: | |
| # propose together | |
| if pais1 in line[0] and pais2 in line[0]: | |
| propose_together += 1 | |
| elif pais1 in line[1] and pais2 in line[1]: | |
| oppose_together += 1 | |
| elif pais1 in line[0] and pais2 in line[1]: | |
| oppose_each_other += 1 | |
| elif pais2 in line[0] and pais1 in line[1]: | |
| oppose_each_other += 1 | |
| print "Conteo de votos de %s versus %s" % (pais1, pais2,) | |
| print "propose_together %i" % propose_together | |
| print "oppose_together %i" % oppose_together | |
| print "oppose_each_other %i" % oppose_each_other | |
| new_lines = [] | |
| chile_se_opone = 0 | |
| for line in lines: | |
| line = re.sub("\s+", " ", line) | |
| line = line.strip() | |
| if line.startswith("Article"): | |
| article_line = line | |
| if "PE" in line and "CL" in line and "US" in line: | |
| tmp = clean_line(line) | |
| if "PE" in tmp[0] and "US" in tmp[0] and "CL" in tmp[1]: | |
| chile_se_opone = chile_se_opone + 1 | |
| print "* %s" % article_line | |
| print line | |
| elif "PE" in tmp[1] and "US" in tmp[1] and "CL" in tmp[0]: | |
| chile_se_opone = chile_se_opone + 1 | |
| print "* %s" % article_line | |
| print line | |
| if line.startswith("["): | |
| new_lines.append(clean_line(line)) | |
| print "Chile se opone a US y PE %i veces" % chile_se_opone | |
| print "Hay %i lineas de informacion" % len(new_lines) | |
| count_countries("PE", "US", new_lines) | |
| print "\n———————\n" | |
| count_countries("PE", "CL", new_lines) | |
| print "\n———————\n" | |
| count_countries("US", "CL", new_lines) |
Como ya saben, hace unos días terminó la discusión, e idas y venidas, acerca del grupo de trabajo de derechos humanos del Congreso, presidido por la congresista fujimorista Martha Chavez (@MarthaChavezK36).
La discusión degeneró tanto que llegó al tuiter. La congresista Martha Chavez anunciaba en tuiter sus planes de trabajo dentro de la comisión y respondía a uno que otro insulto tuitero. Era notable la cantidad de tuits emitidos por la congresista. Pero, fueron muchos tuits? pocos? en qué horas acostumbra tuitar la congresista?
Usando herramientas de Linux, Python y unas cuantas librerías «open source» podemos analizar el comportamiento tuitero de Martha Chavez.
Descargué del tuiter los 3200 tuits más recientes de la congresista. Para eso usé un cliente de tuiter usable desde la consola Linux.
t timeline -c -n 3200 MarthaChavezK36 > MarthaChavezK36.csv
Aquí ven parte de los tuits descargados (click para ampliar).

Hice un gráfico del número de tuits por día, usando Python.

timeline de la congresista Martha Chavez
Este timeline comienza el 24 de julio. Vemos que tuvo bastante actividad el 28 de Julio, mediados de Septiembre (cuando se discutía sobre la unión civil de parejas del mismo sexo), primera y segunda semana de Octubre (en esa época se tuiteaba sobre la renuncia de Fujimori por fax), primera semana de Noviembre (cuando se armó el chongo de su elección como coordinadora del grupo de trabajo sobre derechos humanos).
Parece que su destitución del grupo de DDHH no hizo que Martha Chavez tuitee tanto como cuando se hablaba de la unión civil (muy revelador!).
Pero supongo que Martha Chavez tuitea en sus horas libres, cuando ya terminó sus horas de trabajo en el congreso, además de los fines de semana.
Podemos ver esto si usamos sus tuits para generar un «punchcard»:
python analizar_tuits.py MarthaChavezK36.csv | python punchcard.py -f punchcard_Martha_Chavez.png

Esto es alucinante! La congresista tuitea todos los días de la semana. Tuitea a forro entre las 8 y 10 de la mañana (ni bien llega al Congreso?). Tuitea con mayor fuerza los días Viernes. El menor número de tuits a la 1:00pm hace suponer que a esa hora almuerza. Sábados y Domingos, no descansa, tuitea tanto como los días lunes. Y parece que se va a dormir a la 1:00 am. Al parecer duerme menos de 8 horas (eso no es saludable congresista!).
Este nivel de tuits emitidos por Martha Chavez es muy alto? muy bajo? Podemos hacer una comparación con un tuitero consumado, neto y nato. Comparemos con el Útero de Marita:
Este es el punchcard del utero.pe.

Vemos que, al parecer, el útero.pe tuitea menos que la congresista. Uterope tuitea muy poco los viernes, sábados y domingos (a excepción de las 9:00pm cuando tuitea con furia, debe ser que a esa hora pasan los noticieros dominicales). Qué hace el uterope los viernes y fines de semanas que no tuitea? Debe tener buena vida. También tuitea bastante los jueves.
Aqui les dejo el código necesario para hacer este tipo de análisis (?) con cualquier tuitero. Pero fíjense que el tuitero no ande borrando sus tuits ni use tuits programados ya que malograría el «análisis».
Código para producir el gráfico timeline y producir las fechas en formato unix, necesarias para dibujar el punchcard. El programa que hace el punchard lo saqué de aquí: https://github.com/aaronjorbin/punchcard.py
| #! /usr/bin/env python | |
| # -*- coding: utf-8 -*- | |
| import sys | |
| import codecs | |
| import re | |
| import datetime | |
| import time | |
| from itertools import groupby | |
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| import brewer2mpl | |
| f = codecs.open(sys.argv[1].strip(), "r", "utf-8") | |
| datos = f.readlines() | |
| f.close() | |
| timestamps = [] | |
| counting = [] | |
| x = [] | |
| for line in datos: | |
| line = line.strip() | |
| if re.search("^[0-9]{6,},", line): | |
| line = line.split(",") | |
| fecha = line[1] | |
| unix_time = time.mktime(datetime.datetime.strptime(fecha, "%Y-%m-%d %H:%M:%S +%f").timetuple()) | |
| # correct for local time Lima -5 hours | |
| unix_time -= 60*60*5 | |
| print unix_time | |
| fecha = fecha.split(" ")[0] | |
| my_time = datetime.datetime.strptime(fecha, "%Y-%m-%d") | |
| if my_time not in timestamps: | |
| timestamps.append(my_time) | |
| counting.append(fecha) | |
| if fecha not in x: | |
| x.append(fecha) | |
| # de reversa | |
| timestamp = timestamps[::-1] | |
| y_axis = [len(list(group)) for key, group in groupby(counting)] | |
| # queremos color | |
| set2 = brewer2mpl.get_map('Set2', 'qualitative', 8).mpl_colors | |
| color = set2[0] | |
| fig, ax = plt.subplots(1) | |
| plt.plot(timestamps, y_axis, color=color) | |
| plt.xticks(rotation="45") | |
| plt.ylabel(u"Número de tuits por día") | |
| plt.title(u'Actividad tuitera de Martha Chavez: timeline') | |
| plt.tight_layout() | |
| plt.savefig("timeline" + sys.argv[1].strip() + ".png") | |
| sys.exit() |
Ministros y ex-primer ministros de este gobierno coinciden en pensar que la inseguridad ciudadana es una percepción, ilusión de la gente, producto de estados mentales histéricos y que no hay que quejarse tanto.
Lo cierto es que según los datos del INEI. El número total de delitos a nivel nacional está aumentando:

Figura 1. Número total de delitos. Fuente INEI http://www.inei.gob.pe/media/MenuRecursivo/Cap08005.xls
Una regresión lineal nos confirma la tendencia:

Figura 2. Regresión lineal de número total de delitos versus año.
La regresión lineal (y el gráfico) nos dice que conforme pasan los años ha aumentado la delincuencia (R2 = 0.67) de manera significativa (p-value = 0.008).
Se observa que entre los años 2008 y 2011 ocurrió un punto de quiebre y la delicuencia aumentó, pero no podemos apuntar con precisión en qué año comenzó esta racha de mayor número de delitos. Además que los datos no se ajustan muy bien a la línea de tendencia. Pareciera que el aumento de delitos no es lineal, parece ser exponencial! Esta incertidumbre es parte de las limitaciones de las estadísticas que estoy usando, esta corriente llamada estadísticas frecuentistas.
Pero afortunadamente existen las estadísticas bayesianas que nos pueden dar algo más de información respecto a este tema.
Estas estadísticas nos pueden ayudar a estimar en qué año aumentó la delincuencia. Por ejemplo, el promedio de delitos anuales antes de este incremento puede ser considerado como la variable 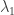
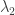
Podemos estimar el rango de valores más probables que puede tener cada variable si es que usamos simulaciones de números aleatorios.
[Paréntesis]
Los estadísticos bayesianos conocen la probabilidad más alta de estos valores como probabilidad posterior. Por ejemplo, cuando tú amig@ lector(a) recibes un email (digamos de Gmail), la empresa Google tiene un software que aplica estadísticas bayesianas al contenido del mensaje. Lo que hace es buscar palabras clave que indiquen que el email recibido es spam. La probabilidad inicial que un mensaje sea Spam puede ser 0.5 (osea 50%), pero si el contenido tiene las palabras «viagra», «penis», «enlargement». Existirá una mayor probabilidad que este correo es spam, (a esta probabilidad se le llama probabilidad posterior ya que se obtiene luego de examinar la evidencia), y el software de Google lo enviará directamente a la carpeta Junk. Por eso las estadísticas bayesianas son importantes, y además las usas a diario sin darte cuenta.
[/Paréntesis]
Volviendo a nuestro problema, necesitamos ver cuáles son las probabilidades posteriores de nuestros datos de número de delitos a nivel nacional. Felizmente, el lenguaje de programación Python tiene una librería muy chévere para hacer estadísticas bayesianas. Es el paquete pymc. Entonces solo es cuestion de simular muchas veces los valores de números totales de delito antes y después del incremento, y el año de incremento en la tasa delincuencial (osea 
Realicé una simulación de 50 mil generaciones usando una cadena Markov Monte Carlo, descarté las primeras 10 mil generaciones y dibujé los resultados:

Vemos que hay una diferencia notable entre el total esperado de delitos antes (
También vemos que es más probable que en el 6to año (osea año 2011) ocurrió la aceleración de la delincuencia en el Perú.
Podemos combinar estas tres variables en un solo gráfico:

Este gráfico muestra los valores esperados de delito antes, después y durante la aceleración en el nivel de delicuencia. Vemos que esto ocurrió del año 2010 al 2011.
Ahora, pregunto qué acontecimiento ocurrió entre 2010 y 2011 que fue el causante del aumento de la delicuencia en nuestro país? El que sepa «que levante la mano».
Aquí los datos que he usado:
| 152516 | |
| 153055 | |
| 144205 | |
| 151560 | |
| 160848 | |
| 181866 | |
| 206610 | |
| 254405 |
Auí está el código para hacer la regresión lineal en R:
| library(ggplot2) | |
| y <- read.csv("datos.txt", header=FALSE) | |
| y <- as.vector(y[,1]) | |
| x <- 2005:2012 | |
| int <- lsfit(x,y)$coefficients[1] | |
| slope <- lsfit(x,y)$coefficients[2] | |
| p <- ggplot(,aes(x,y)) | |
| p + geom_point() + geom_abline(intercept=int, slope=slope) + | |
| labs(title = "Perú: Número total de delitos por año") | |
| summary(lm(x ~ y)) | |
| # R2 = 0.67 | |
| # p-value = 0.008 |
Aquí el código para hacer el análisis bayesiano (usa Python, pymc, y prettyplotlib):
| # -*- coding: utf-8 -*- | |
| import prettyplotlib as ppl | |
| from prettyplotlib import plt | |
| import sys | |
| import pymc as pm | |
| import numpy as np | |
| datos = np.loadtxt("datos.txt") | |
| alpha = 1.0/datos.mean() | |
| print alpha | |
| print "alpha %f" % alpha | |
| print "datos.mean %f" % datos.mean() | |
| n_datos = len(datos) | |
| lambda_1 = pm.Exponential("lambda_1", alpha) | |
| lambda_2 = pm.Exponential("lambda_2", alpha) | |
| print lambda_1.random() | |
| print lambda_2.random() | |
| tau = pm.DiscreteUniform("tau", lower=0, upper=n_datos) | |
| print tau.random() | |
| @pm.deterministic | |
| def lambda_(tau=tau, lambda_1=lambda_1, lambda_2=lambda_2): | |
| out = np.zeros(n_datos) | |
| out[:tau] = lambda_1 | |
| out[tau:] = lambda_2 | |
| return out | |
| observation = pm.Poisson("obs", lambda_, value=datos, observed=True) | |
| model = pm.Model([observation, lambda_1, lambda_2, tau]) | |
| mcmc = pm.MCMC(model) | |
| mcmc.sample(50000, 10000, 1) | |
| lambda_1_samples = mcmc.trace('lambda_1')[:] | |
| lambda_2_samples = mcmc.trace('lambda_2')[:] | |
| tau_samples = mcmc.trace('tau')[:] | |
| fig, (ax1, ax2, ax3) = plt.subplots(nrows=3, ncols=1) | |
| plt.rc('font', **{'family': 'DejaVu Sans'}) | |
| plt.subplot(311) | |
| plt.title(u'''Distribución posterior de las variables | |
| $\lambda_1,\;\lambda_2,\;tau$''') | |
| plt.hist(lambda_1_samples, histtype="stepfilled", bins=30, alpha=0.85, | |
| normed=True) | |
| plt.xlim([150000,250000]) | |
| plt.xlabel("valor de $\lambda_1$") | |
| plt.subplot(312) | |
| #ax.set_autoscaley_on(False) | |
| plt.hist(lambda_2_samples, histtype="stepfilled", bins=30, alpha=0.85, | |
| normed=True) | |
| plt.xlim([150000,250000]) | |
| plt.xlabel("valor de $\lambda_2$") | |
| plt.tick_params(axis="both", which="mayor", labelsize=4) | |
| plt.subplot(313) | |
| w = 1.0/tau_samples.shape[0]*np.ones_like(tau_samples) | |
| plt.hist(tau_samples, bins=n_datos, alpha=1, weights=w, rwidth=2.0) | |
| plt.xticks(np.arange(n_datos)) | |
| plt.ylim([0, 1.5]) | |
| plt.xlim([0, 8]) | |
| plt.xlabel("valor de $tau$") | |
| fig.set_size_inches(7,6) | |
| fig.tight_layout() | |
| fig.savefig("plot1.png") | |
| fig, ax = plt.subplots(nrows=1, ncols=1) | |
| N = tau_samples.shape[0] | |
| expected_texts_per_day = np.zeros(n_datos) | |
| for day in range(0, n_datos): | |
| ix = day < tau_samples | |
| expected_texts_per_day[day] = (lambda_1_samples[ix].sum() | |
| + lambda_2_samples[~ix].sum()) / N | |
| anhos = ["2005","2006","2007","2008","2009","2010","2011","2012"] | |
| plt.plot(range(n_datos), expected_texts_per_day, lw=4, color="#E24A33", | |
| label="expected number of text-messages received") | |
| plt.xlim(0, n_datos) | |
| plt.xticks(np.arange(n_datos) + 0.4, anhos) | |
| plt.xlabel(u'Años') | |
| plt.ylabel(u'Número esperado de delitos') | |
| plt.title(u'''Cambio en el número esperado de delitos por año''') | |
| plt.ylim(0, 300000) | |
| plt.bar(np.arange(len(datos)), datos, color="#348ABD", alpha=0.65) | |
| #plt.legend(loc="upper left") | |
| fig.savefig("plot2.png") |
El último reportaje de la saga #intervenganAPDAYC se está transmitiendo desde el Congreso del República (30-Oct-2013). Además el útero de marita acaba de publicar una base de datos interactiva con toda la repartición de las regalías que cobró APDAYC durante el 2012. También hay una hoja de ruta para intervenir APDAYC.
Es ya conocido que Radio Inspiración maneja muchas radios vía la Fundación Autor que está ligada a APDAYC. Esta cadena de radios pasa muchas canciones y queríamos averiguar si hay algún patrón interesante en aquellas canciones que son más difundidas y repetidas en su programación. Por ejemplo, qué canciones tienen como autores a los directivos de APDAYC?, cuáles pertenecen al catálogo de las empresas que están íntimamente relacionadas con APDAYC? (E.T. Music?, IEPMSA?)
Para eso hice una acumulación y tabulación de los datos de las canciones más toneras de Radio Inspiración (aquí están los rankings). La resolución de las imágenes era mínima y no se pudo hacer OCR. Entonces tuve que tipear las canciones una por una. Felizmente no eran muchas.
Luego era cuestión de juntar toda la información en un sólo archivo y hacer el plot usando funciones estadísticas del lenguaje de programación Python.

Canciones de Radio Inspiración del top10 que son más frecuentes.

Canciones de Radio Inspiración que son más frecuentes en el top20
Sería interesante averiguar quiénes son los autores de esas canciones top-10. En teoría se podría ver cuáles son las canciones que pertenecen a cada autor y compositor registrado en APDAYC. Pero creo que eso es pedir demasiada transparencia.
Aquí el código para dibujar el gráfico:
Previa limpieza de datos:
cat all_data.csv | awk -F ',' '{print $2}' | sort | uniq -c | sort -hr | sed 's/^\s\+//g' | grep -v '1 ' | sed -r 's/^([0-9]+)\s+/\1,/g' > tmp
| # -*- coding: utf-8 -*- | |
| import prettyplotlib as ppl | |
| import numpy as np | |
| from prettyplotlib import plt | |
| import csv | |
| from array import array | |
| import collections | |
| """ Top 10 ranking """ | |
| x = [] | |
| y = [] | |
| ranks = ["1","2","3","4","5","6","7","8","9","10","maxima"] | |
| with open("all_data.csv", "rb") as csvfile: | |
| f = csv.reader(csvfile, delimiter=",") | |
| for row in f: | |
| print row | |
| if row[0] in ranks: | |
| x.append(row[1]) | |
| counter = collections.Counter(x) | |
| x = [] | |
| y = [] | |
| for i in sorted(counter, key=counter.get, reverse=True): | |
| if counter[i] != 1: | |
| x.append(i) | |
| y.append(counter[i]) | |
| for i in range(len(x)): | |
| print str(y[i]) + "," + str(x[i]) | |
| plt.rc('font', **{'family': 'DejaVu Sans'}) | |
| fig, ax = plt.subplots(1, figsize=(20,6)) | |
| width = 0.35 | |
| ind = np.arange(len(y)) | |
| xdata = ind + 0.05 + width | |
| ax.bar(ind, y) | |
| ax.set_xticks(ind + 0.5) | |
| ax.set_xticklabels(x, rotation="vertical") | |
| ax.autoscale() | |
| ax.set_title(u'Ranking de canciones "Top 10"\n Radio Inspiraci贸n FM', | |
| fontdict = {'fontsize':24} | |
| ) | |
| plt.ylabel('Frecuencia en "Top 10"', fontdict={'fontsize':18}) | |
| plt.xlabel(u"Canci贸n", fontdict={'fontsize':22}) | |
| ppl.bar(ax, np.arange(len(y)), y, grid="y") | |
| fig.tight_layout() | |
| fig.savefig("top10.png") | |
| # -*- coding: utf-8 -*- | |
| import prettyplotlib as ppl | |
| import numpy as np | |
| from prettyplotlib import plt | |
| import csv | |
| from array import array | |
| """ Top 20 ranking """ | |
| x = [] | |
| y = [] | |
| with open("tmp", "rb") as csvfile: | |
| f = csv.reader(csvfile, delimiter=",") | |
| for row in f: | |
| print row | |
| x.append(row[1]) | |
| y.append(row[0]) | |
| # converts strings to int | |
| y = map(int,y) | |
| print x | |
| print y | |
| plt.rc('font', **{'family': 'DejaVu Sans'}) | |
| fig, ax = plt.subplots(1, figsize=(20,6)) | |
| width = 0.35 | |
| ind = np.arange(len(y)) | |
| xdata = ind + 0.05 + width | |
| ax.bar(ind, y) | |
| ax.set_xticks(ind + 0.5) | |
| ax.set_xticklabels(x, rotation="vertical") | |
| ax.autoscale() | |
| ax.set_title(u'Ranking de canciones "Top 20"\n Radio Inspiraci贸n FM', | |
| fontdict = {'fontsize':24} | |
| ) | |
| plt.ylabel('Frecuencia en "Top 20"', fontdict={'fontsize':18}) | |
| plt.xlabel(u"Canci贸n", fontdict={'fontsize':22}) | |
| ppl.bar(ax, np.arange(len(y)), y, grid="y") | |
| #fig.tight_layout() | |
| fig.savefig("top20.png") |
Aquí los datos:
| maxima | lejos de ti | |
|---|---|---|
| 1 | El baile del caballo | |
| 1 | Opam kay kasja | |
| 2 | donde esta el amor | |
| 3 | ya no sere tu panuelito | |
| 4 | ai se eu te pego | |
| 5 | tu ausencia | |
| 6 | hoy he vuelto a ver el amor | |
| 7 | intentalo | |
| 8 | linda wawita | |
| 9 | si me vas a abandonar | |
| 10 | tirate un paso | |
| 11 | balada boa | |
| 12 | el ritmo de mi corazon | |
| 13 | pedacito de mi vida | |
| 14 | la pregunta | |
| 15 | canto herido | |
| 16 | corre | |
| 17 | me prefieres a mi | |
| 18 | el amor que perdimos | |
| 19 | el teke teke | |
| 20 | no te recuerdo | |
| revelacion | festroni-k | |
| 21 | el dinero | |
| 21 | el cuchi cuchi | |
| 22 | tento tu love | |
| 23 | virgen | |
| 23 | en aquel lugar | |
| 24 | si te vas que hare | |
| 24 | te burlabas de mi | |
| 25 | bombon asesino | |
| 26 | chora me liga | |
| 27 | la escobita | |
| 27 | gitana | |
| 28 | mil heridas | |
| 29 | la borrachita | |
| 29 | como te olvido | |
| 30 | te dejo en libertad | |
| 31 | cuando se pierde un amor | |
| 32 | se me ha perdido el corazon | |
| 33 | te eche al olvido | |
| 34 | te amare | |
| 35 | que pena | |
| 36 | curandero de amor | |
| 37 | la borrachita | |
| 37 | dutty love | |
| 38 | corazon herido | |
| 39 | te extrano tanto | |
| 40 | mr saxobeat | |
| 41 | acabame | |
| 41 | estar sin ti | |
| 42 | corazon embustero | |
| 43 | obsesion | |
| 44 | ya no te aguanto | |
| 44 | tirana | |
| 45 | no te voy a preguntar | |
| 46 | he vuelto por ti | |
| 46 | te va a doler | |
| 47 | si me tenias | |
| 48 | esta noche | |
| 49 | buscandote | |
| 50 | danza kuduro | |
| maxima | bara bere | |
| 1 | mi estrella | |
| 2 | el baile de la gallina | |
| 3 | tu me cambiaste la vida | |
| 4 | tu nombre | |
| 5 | more | |
| 6 | diganle | |
| 7 | domitila | |
| 8 | volvi a nacer | |
| 9 | aprendere | |
| 10 | el amor esta pero viene y se va | |
| 11 | como le explico a mi corazon | |
| 12 | vete lejos | |
| 13 | el baile del tao/el meneito arrebatao | |
| 14 | leyes del corazon | |
| 15 | alejate de mi | |
| maxima | bara bere | |
| 1 | mi estrella | |
| 2 | more | |
| 3 | el baile de la gallina | |
| 4 | volvi a nacer | |
| 5 | tu me cambiaste la vida | |
| 6 | camuflaje | |
| 7 | diganle | |
| 8 | domitila | |
| 9 | tu nombre | |
| 10 | el amor esta pero viene y se va | |
| 11 | aprendere | |
| 12 | leyes del corazon | |
| 13 | vete lejos | |
| 14 | como le explico a mi corazon | |
| 15 | el baile del tao/el meneito arrebatao | |
| maxima | el baile de la gallina | |
| 1 | tu nombre | |
| 2 | tu me cambiaste la vida | |
| 3 | aprendere | |
| 4 | el baile del tao/el meneito arrebatao | |
| 5 | bara bere | |
| 6 | diganle | |
| 7 | vete lejos | |
| 8 | el amor esta pero viene y se va | |
| 9 | mi estrella | |
| 10 | como le explico a mi corazon | |
| 11 | leyes del corazon | |
| 12 | more | |
| 13 | domitila | |
| 14 | alejate de mi | |
| 15 | volvi a nacer | |
| maxima | tu nombre | |
| 1 | el baile del tao/el meneito arrebatao | |
| 2 | vete lejos | |
| 3 | aprendere | |
| 3 | diganle | |
| 4 | el baile de la gallina | |
| 5 | mi estrella | |
| 6 | el amor esta pero viene y se va | |
| 7 | leyes del corazon | |
| 8 | tu me cambiaste la vida | |
| 9 | como le explico a mi corazon | |
| 10 | bara bere | |
| 11 | alejate de mi | |
| 12 | el dinero | |
| 13 | domitila | |
| 14 | more | |
| 15 | volvi a nacer | |
| maxima | tu nombre | |
| 1 | el baile del tao/el meneito arrebatao | |
| 2 | vete lejos | |
| 3 | aprendere | |
| 4 | leyes del corazon | |
| 5 | mi estrella | |
| 6 | el amor esta pero viene y se va | |
| 7 | como le explico a mi corazon | |
| 8 | el dinero | |
| 9 | el baile de la gallina | |
| 10 | alejate de mi | |
| 11 | diganle | |
| 12 | tu me cambiaste la vida | |
| 13 | bara bere | |
| 14 | cuando el amor se acaba | |
| 15 | domitila | |
| maxima | el baile del tao/el meneito arrebatao | |
| 1 | aprendere | |
| 2 | vete lejos | |
| 3 | tu nombre | |
| 4 | mi estrella | |
| 5 | leyes del corazon | |
| 6 | el dinero | |
| 7 | el amor esta pero viene y se va | |
| 8 | como le explico a mi corazon | |
| 9 | alejate de mi | |
| 10 | el baile de la gallina | |
| 11 | cuando el amor se acaba | |
| 12 | tu me cambiaste la vida | |
| 13 | se fue mi amor | |
| 14 | diganle | |
| 15 | bara bere | |
| maxima | aprendere | |
| 1 | vete lejos | |
| 2 | el baile del tao/el meneito arrebatao | |
| 3 | leyes del corazon | |
| 4 | el dinero | |
| 5 | como le explico a mi corazon | |
| 6 | alejate de mi | |
| 7 | tu nombre | |
| 8 | mi estrella | |
| 9 | cuando el amor se acaba | |
| 10 | el amor esta pero viene y se va | |
| 11 | mix celeste | |
| 12 | se fue mi amor | |
| 13 | fria | |
| 14 | el baile de la gallina | |
| 15 | limbo | |
| maxima | aprendere | |
| 1 | vete lejos | |
| 2 | el dinero | |
| 3 | leyes del corazon | |
| 4 | cuando se acaba el amor | |
| 5 | mix celeste | |
| 6 | alejate de mi | |
| 7 | fria | |
| 7 | como le explico a mi corazon | |
| 8 | se fue mi amor | |
| 9 | el baile del tao/el meneito arrebatao | |
| 10 | aguita de coco | |
| 11 | tu nombre | |
| 12 | mi estrella | |
| 13 | el amor esta pero viene y se va | |
| 14 | limbo | |
| 15 | todo me da vueltas | |
| maxima | aprendere | |
| 1 | el dinero | |
| 2 | mix celeste | |
| 3 | cuando se acaba el amor | |
| 4 | fria | |
| 5 | alejate de mi | |
| 6 | se fue mi amor | |
| 7 | aguita de coco | |
| 8 | vete lejos | |
| 9 | el baile del tao/el meneito arrebatao | |
| 9 | todo me da vueltas | |
| 10 | leyes del corazon | |
| 11 | tu nombre | |
| 12 | como le explico a mi corazon | |
| 13 | limbo | |
| 14 | un loco amor | |
| 15 | hasta que salga el sol | |
| maxima | mix celeste | |
| 1 | el dinero | |
| 2 | cuando el amor se acaba | |
| 3 | aprendere | |
| 4 | fria | |
| 5 | aguita de coco | |
| 6 | se fue mi amor | |
| 7 | leyes del corazon | |
| 8 | alejate de mi | |
| 9 | el baile del tao/el meneito arrebatao | |
| 10 | un loco amor | |
| 11 | vete lejos | |
| 12 | hasta que salga el sol | |
| 13 | limbo | |
| 14 | llora llora corazon | |
| 15 | tu nombre | |
| maxima | el dinero | |
| 1 | cuando el amor se acaba | |
| 2 | aguita de coco | |
| 3 | mix celeste | |
| 4 | fria | |
| 5 | se fue mi amor | |
| 6 | todo me da vueltas | |
| 7 | leyes del corazon | |
| 8 | un loco amor | |
| 9 | hasta que salga el sol | |
| 10 | llora llora corazon | |
| 11 | alejate de mi | |
| 12 | aprendere | |
| 12 | como te olvido | |
| 13 | el baile del tao/el meneito arrebatao | |
| 14 | limbo | |
| 15 | vete lejos | |
| maxima | el dinero | |
| 1 | aguita de coco | |
| 2 | mix celeste | |
| 3 | fria | |
| 4 | se fue mi amor | |
| 5 | todo me da vueltas | |
| 6 | hasta que salga el sol | |
| 7 | como te olvido | |
| 8 | un loco amor | |
| 9 | llora llora corazon | |
| 9 | cuando el amor se acaba | |
| 10 | leyes del corazon | |
| 11 | alejate de mi | |
| 12 | donde estaras | |
| 13 | por eso te amo | |
| 14 | puro cuento | |
| 15 | aprendere | |
| maxima | aguita de coco | |
| 1 | fria | |
| 2 | se fue mi amor | |
| 3 | hasta que salga el sol | |
| 4 | todo me da vueltas | |
| 5 | el dinero | |
| 6 | mix celeste | |
| 6 | como te olvido | |
| 7 | un loco amor | |
| 8 | llora llora corazon | |
| 9 | por eso te amo | |
| 10 | leyes del corazon | |
| 11 | donde estaras | |
| 12 | yo te lo dije | |
| 13 | puro cuento | |
| 14 | alejate de mi | |
| 15 | el pegao | |
| maxima | fria | |
| 1 | hasta que salga el sol | |
| 2 | se fue mi amor | |
| 3 | aguita de coco | |
| 4 | todo me da vueltas | |
| 5 | como te olvido | |
| 6 | un loco amor | |
| 7 | por eso te amo | |
| 8 | llora llora corazon | |
| 9 | el dinero | |
| 9 | leyes del corazon | |
| 10 | yo te lo dije | |
| 11 | donde estaras | |
| 12 | parranda amor amor | |
| 13 | puro cuento | |
| 14 | el pegao | |
| 15 | mix celeste | |
| maxima | fria | |
| 1 | hasta que salga el sol | |
| 2 | se fue mi amor | |
| 3 | por eso te amo | |
| 4 | como te olvido | |
| 5 | un loco amor | |
| 6 | llora corazon llora | |
| 7 | aguita de coco | |
| 8 | yo te lo dije | |
| 9 | todo me da vueltas | |
| 10 | donde estaras | |
| 10 | parranda amor amor | |
| 11 | puro cuento | |
| 12 | el pegao | |
| 13 | ella se fue llorando | |
| 14 | carita de pasaporte | |
| 15 | el dinero | |
| 15 | leyes del corazon | |
| maxima | hasta que salga el sol | |
| 1 | se fue mi amor | |
| 2 | por eso te amo | |
| 3 | como te olvido | |
| 4 | un loco amor | |
| 5 | fria | |
| 5 | llora corazon llora | |
| 6 | parranda amor amor | |
| 7 | yo te lo dije | |
| 8 | donde estaras | |
| 9 | puro cuento | |
| 9 | el pegao | |
| 10 | ella se fue llorando | |
| 11 | carita de pasaporte | |
| 12 | aguita de coco | |
| 13 | amigo mio | |
| 14 | zumba | |
| 15 | todo me da vueltas | |
| maxima | hasta que salga el sol | |
| 1 | por eso te amo | |
| 2 | como te olvido | |
| 3 | llora corazon llora | |
| 3 | parranda amor amor | |
| 4 | un loco amor | |
| 5 | se fue mi amor | |
| 6 | yo te lo dije | |
| 7 | carita de pasaporte | |
| 8 | donde estaras | |
| 8 | ella se fue llorando | |
| 9 | puro cuento | |
| 9 | el pegao | |
| 10 | fria | |
| 11 | amigo mio | |
| 12 | zumba | |
| 13 | lastima | |
| 14 | el amor mas grande del planeta | |
| 15 | aguita de coco | |
| maxima | por eso te amo | |
| 1 | como te olvido | |
| 1 | parranda amor amor | |
| 2 | llora corazon llora | |
| 2 | un loco amor | |
| 3 | yo te lo dije | |
| 4 | carita de pasaporte | |
| 5 | amigo mio | |
| 6 | ella se fue llorando | |
| 6 | el pegao | |
| 7 | el amor mas grande del planeta | |
| 8 | zumba | |
| 9 | lastima | |
| 10 | puro cuento | |
| 11 | caprichos del corazon | |
| 12 | mi corazon esta llorandote | |
| 13 | princesa | |
| 14 | tu poeta | |
| 15 | hasta que salga el sol | |
| 15 | donde estaras | |
| maxima | por eso te amo | |
| 1 | como te olvido | |
| 2 | parranda amor amor | |
| 2 | llora corazon llora | |
| 3 | un loco amor | |
| 4 | yo te lo dije | |
| 5 | carita de pasaporte | |
| 6 | hasta que salga el sol | |
| 7 | ella se fue llorando | |
| 7 | puro cuento | |
| 8 | el pegao | |
| 9 | amigo mio | |
| 10 | el amor mas grande del planeta | |
| 11 | zumba | |
| 12 | donde estaras | |
| 12 | lastima | |
| 13 | se fue mi amor | |
| 13 | caprichos del corazon | |
| 14 | mi corazon esta llorandote | |
| 15 | fria | |
| maxima | como te olvido | |
| 1 | parranda amor amor | |
| 2 | yo te lo dije | |
| 3 | carita de pasaporte | |
| 3 | amigo mio | |
| 4 | por eso te amo | |
| 5 | llora corazon llora | |
| 5 | ella se fue llorando | |
| 6 | el amor mas grande del planeta | |
| 7 | un loco amor | |
| 7 | zumba | |
| 8 | lastima | |
| 9 | el pegao | |
| 9 | caprichos del corazon | |
| 10 | mi corazon esta llorandote | |
| 11 | princesa | |
| 12 | hay que saber perder | |
| 13 | tu poeta | |
| 14 | te extrano tanto | |
| 14 | cuando me acuerdo de ti | |
| 15 | puro cuento | |
| maxima | parranda amor amor | |
| 1 | carita de pasaporte | |
| 1 | amigo mio | |
| 2 | yo te lo dije | |
| 3 | como te olvido | |
| 4 | ella se fue llorando | |
| 5 | zumba | |
| 6 | lastima | |
| 6 | caprichos del corazon | |
| 7 | mi corazon esta llorandote | |
| 8 | por eso te amo | |
| 9 | un loco amor | |
| 10 | te extrano tanto | |
| 11 | llora corazon llora | |
| 11 | hay que saber perder | |
| 12 | tu poeta | |
| 13 | cuando me acuerdo de ti | |
| 14 | algo que decir | |
| 15 | el pegao | |
| maxima | parranda amor amor | |
| 1 | carita de pasaporte | |
| 1 | amigo mio | |
| 2 | yo te lo dije | |
| 3 | ella se fue llorando | |
| 3 | el amor mas grande del planeta | |
| 4 | lastima | |
| 4 | mi corazon esta llorandote | |
| 5 | zumba | |
| 6 | caprichos del corazon | |
| 7 | princesa | |
| 8 | te extrano tanto | |
| 9 | hay que saber perder | |
| 10 | como te olvido | |
| 11 | tu poeta | |
| 12 | cuando me acuerdo de ti | |
| 13 | por eso te amo | |
| 13 | algo que decir | |
| 14 | te olvidare | |
| 15 | llora corazon llora | |
| maxima | amigo mio | |
| 1 | yo te lo dije | |
| 1 | ella se fue llorando | |
| 2 | parranda amor amor | |
| 2 | el amor mas grande del planeta | |
| 3 | mi corazon esta llorandote | |
| 4 | zumba | |
| 4 | princesa | |
| 5 | carita de pasaporte | |
| 5 | caprichos del corazon | |
| 6 | te extrano tanto | |
| 7 | lastima | |
| 7 | tu poeta | |
| 8 | hay que saber perder | |
| 8 | te olvidare | |
| 9 | cuando me acuerdo de ti | |
| 10 | algo que decir | |
| 11 | vivir mi vida | |
| 12 | tan solo un minuto | |
| 13 | si tu me faltas | |
| 14 | como te olvido | |
| 15 | un loco amor | |
| 16 | llora corazon llora | |
| 17 | hasta que salga el sol | |
| 18 | me enamore | |
| 19 | angel en zapatillas | |
| 19 | hasta el fin del mundo | |
| 20 | asi no | |
| maxima | ella se fue llorando | |
| 1 | el amor mas grande del planeta | |
| 2 | mi corazon esta llorandote | |
| 3 | yo te lo dije | |
| 3 | princesa | |
| 4 | zumba | |
| 4 | caprichos del corazon | |
| 5 | amigo mio | |
| 5 | te extrano tanto | |
| 6 | lastima | |
| 6 | tu poeta | |
| 7 | hay que saber perder | |
| 7 | cuando me acuerdo de ti | |
| 8 | parranda amor amor | |
| 8 | te olvidare | |
| 9 | tan solo un minuto | |
| 10 | algo que decir | |
| 11 | vivir mi vida | |
| 12 | carita de pasaporte | |
| 12 | si tu me faltas | |
| 13 | hasta el fin del mundo | |
| 14 | me enamore | |
| 15 | angel en zapatillas | |
| 16 | asi no | |
| 17 | festroni-k | |
| 18 | como te olvido | |
| 18 | llora corazon llora | |
| 19 | un loco amor | |
| 20 | hasta que salga el sol | |
| maxima | el amor mas grande del planeta | |
| 1 | mi corazon esta llorandote | |
| 1 | princesa | |
| 2 | ella se fue llorando | |
| 3 | caprichos del corazon | |
| 4 | zumba | |
| 4 | lastima | |
| 5 | tu poeta | |
| 5 | hay que saber perder | |
| 6 | cuando me acuerdo de ti | |
| 6 | te olvidare | |
| 7 | tan solo un minuto | |
| 8 | amigo mio | |
| 8 | te extrano tanto | |
| 9 | algo que decir | |
| 10 | vivir mi vida | |
| 11 | si tu me faltas | |
| 11 | festroni-k | |
| 12 | hasta el fin del mundo | |
| 13 | parranda amor amor | |
| 13 | me enamore | |
| 14 | asi no | |
| 15 | angel en zapatillas | |
| 16 | yo te lo dije | |
| 17 | carita de pasaporte | |
| 18 | el tiempo | |
| 19 | para siempre | |
| 20 | como te olvido | |
| maxima | mi corazon esta llorandote | |
| 1 | princesa | |
| 2 | el amor mas grande del planeta | |
| 2 | caprichos del corazon | |
| 3 | lastima | |
| 3 | tu poeta | |
| 4 | te olvidare | |
| 5 | hay que saber perder | |
| 6 | cuando me acuerdo de ti | |
| 6 | vivir mi vida | |
| 7 | tan solo un minuto | |
| 8 | ella se fue llorando | |
| 8 | zumba | |
| 9 | algo que decir | |
| 9 | hasta el fin del mundo | |
| 10 | festroni-k | |
| 11 | si tu me faltas | |
| 11 | me enamore | |
| 12 | asi no | |
| 13 | amigo mio | |
| 14 | angel en zapatillas | |
| 15 | te extrano tanto | |
| 16 | el tiempo | |
| 17 | para siempre | |
| 18 | parranda amor amor | |
| 18 | carita de pasaporte | |
| 19 | perdon | |
| 19 | lo que un dia fue no sera | |
| 20 | yo te lo dije | |
| maxima | mi corazon esta llorandote | |
| 1 | princesa | |
| 1 | caprichos del corazon | |
| 2 | lastima | |
| 2 | tu poeta | |
| 3 | te olvidare | |
| 4 | hay que saber perder | |
| 5 | cuando me acuerdo de ti | |
| 5 | vivir mi vida | |
| 6 | tan solo un minuto | |
| 7 | el amor mas grande del planeta | |
| 7 | hasta el fin del mundo | |
| 8 | algo que decir | |
| 8 | festroni-k | |
| 9 | ella se fue llorando | |
| 10 | si tu me faltas | |
| 10 | asi no | |
| 11 | me enamore | |
| 12 | para siempre | |
| 13 | angel en zapatillas | |
| 14 | el tiempo | |
| 15 | zumba | |
| 16 | amigo mio | |
| 16 | te extrano tanto | |
| 17 | lo que un dia fue no sera | |
| 18 | carita de pasaporte | |
| 18 | perdon | |
| 19 | vete | |
| 20 | parranda amor amor | |
| maxima | princesa | |
| 1 | caprichos del corazon | |
| 1 | tu poeta | |
| 2 | mi corazon esta llorandote | |
| 2 | te olvidare | |
| 3 | vivir mi vida | |
| 4 | hay que saber perder | |
| 4 | cuando me acuerdo de ti | |
| 5 | hasta el fin del mundo | |
| 6 | lastima | |
| 7 | festroni-k | |
| 8 | algo que decir | |
| 9 | asi no | |
| 10 | me enamore | |
| 10 | para siempre | |
| 11 | el amor mas grande del planeta | |
| 12 | lo que un dia fue no sera | |
| 13 | angel en zapatillas | |
| 13 | el tiempo | |
| 14 | ella se fue llorando | |
| 15 | si tu me faltas | |
| 15 | vete | |
| 16 | zumba | |
| 17 | te extrano tanto | |
| 17 | perdon | |
| 18 | amigo mio | |
| 19 | carita de pasaporte | |
| 20 | soy soltera y hago lo | |
| maxima | caprichos del corazon | |
| 1 | tu poeta | |
| 1 | te olvidare | |
| 2 | vivir mi vida | |
| 3 | princesa | |
| 3 | hasta el fin del mundo | |
| 4 | hay que saber perder | |
| 4 | cuando me acuerdo de ti | |
| 5 | lastima | |
| 6 | festroni-k | |
| 6 | asi no | |
| 7 | para siempre | |
| 8 | me enamore | |
| 8 | lo que un dia fue no sera | |
| 9 | tan solo un minuto | |
| 10 | el tiempo | |
| 11 | mi corazon esta llorandote | |
| 11 | el amor mas grande del planeta | |
| 12 | soy soltera y hago lo | |
| 13 | algo que decir | |
| 14 | ella se fue llorando | |
| 14 | vete | |
| 15 | perdon | |
| 16 | angel en zapatillas | |
| 17 | te extrano tanto | |
| 18 | tributo a la cumbia | |
| 19 | carita de pasaporte | |
| 19 | amigo mio | |
| 20 | zumba |
Hay muchos niños que han caído enfermos por comer productos del programa Qali Warma. Entonces la situación es tan grave que se debe eliminar el programa del todo? Qué dicen los datos duros?
Para comenzar hay que recopilar los datos. Por ejemplo usando la etiqueta Qali Warma, se pueden listar todas las noticias aparecidas en El Comercio desde Mayo del 2012 donde se anunció la creación del programa:
http://elcomercio.pe/tag/370678/qali-warma
Y se puede extraer el número de niños intoxicados por fechas. Para complementar los datos se puede buscar en Google noticias adicionales de intoxicados que no hayan aparecido en El Comercio. En un editorial de El Comercio se menciona 400 niños intoxicados pero no hay ningún enlace hacia los datos. He hecho una recopilación rápida con las notas de prensa de intoxicaciones a lo largo del año y solo pude contar 321 niños intoxicados. Aquí verán la información por lugar, fecha, número de niños afectados y enlace a la nota de prensa.
| Loreto | 2013-10-25 | 80 | http://bit.ly/18YdMbA | |
|---|---|---|---|---|
| Junin | 2013-09-28 | 35 | http://bit.ly/18qqNpT | |
| Curahuasi | 2013-09-18 | 50 | http://bit.ly/18qqEmx | |
| Huanuco | 2013-04-18 | 17 | http://bit.ly/18qqzPL | |
| Urubamba | 2013-04-15 | 100 | http://bit.ly/18qqlYX | |
| Ucayali | 2013-10-05 | 15 | http://bit.ly/18qqfAm | |
| Satipo | 2013-09-27 | 24 | http://bit.ly/18YeiGx |
El número total de niños que atiende Qali Warma es 3.5 millones según Rosa María Palacios.
Para hacer una infografía usando círculos, podemos dibujar el tamaño (área) del círculo de tal manera que esté en función del número de niños intoxicados y no intoxicados. Por ejemplo:
Número total de niños intoxicados: 321
Si el área del círculo es 
Número total de niños muertos: 0
Número total de niños no intoxicados: 3.5 millones menos 321
Ya tenemos los valores del radio y podemos dibujar las circunferencias en la misma escala:

Intoxicados por comer Qali Warma en perspectiva
Debería anularse Qali Warma? Bueno, los datos en esta infografía hablan solos.
El programa de alimentación a niños en edad escolar ha sido atacado estas últimas semanas. Uno de los ataques principales viene de un estudio académico de un profesor de Economía de la Universidad de Pacífico. Se pueden bajar el reporte de aquí: http://srvnetappseg.up.edu.pe/siswebciup/Files/DD1307%20-%20Vasquez.pdf
Estuve mirando rápidamente el reporte en cuestión y vi que una de las críticas se basa en una mala interpretación de al menos uno de los análisis estadísticos.
En la página 93 dice:
El Gráfico 50 muestra los resultados obtenidos para el caso de los escolares. En este caso se comparó el gasto presupuestado por escolar contra el porcentaje de niños entre 6 y 11 años que viven en hogares con déficit calórico, información basada en los resultados del IPM. Este muestra resultados preocupantes, a diferencia del caso para preescolares: se observa una relación negativa entre ambas variables. Esto quiere decir que el presupuesto por escolar no está distribuido equitativamente, pues es mayor en los departamentos con menor déficit calórico.
Este es el gráfico 50:

Al ojo se ve que no hay relación entre las variables. Copié los datos que están en la tabla 31 (de la página 123) y ajusté una regresión lineal en el programa estadístico R.
Mira los puntos todos aglomerados al centro. No dejes que la línea de tendencia te engañe. El coeficiente de determinación R2 es casi cero (0.04) y el p-value no es significativo ( p > 0.05).
Tarán! los resultados dicen que NO hay correlación entre las variables y que las conclusiones del autor de líneas arriba están erradas. NO es cierto que los datos indiquen que se gaste menos dinero en áreas con mayor deficiencia calórica.

Si hubiera una correlación entre dos variables, osea una relación entre gasto y nivel de deficiencia calórica, deberíamos de tener un gráfico así. Mira los puntos distribuidos a lo largo de la línea de tendencia, no están aglomerados!:

Ejemplo de correlación significativa
Hay obvia correlación, a mayor valor de x, menor valor de y. Además los valores de R2 y p-value son: R2 = 0.82, p = 0.0002. El coeficiente R2 es cercano a 1, y el p-value es mucho menor que 0.05. Osea altamente significativo.
Pero los valores que salen de analizar los datos del estudio académico son los siguientes:
R2 = 0.04 (es casi cero, si fuera cercano a 1 sabes que hay correlación. Pero en este caso no tiene nada!)
p = 0.157 (es mayor que 0.05, osea datos no significativos).
Ya ves chocherita, no hay tendencia, no hay correlación, no hay causación. Señores, no tiene nada!
El autor del estudio académico da como ejemplo (pag. 93) que en Puno (con alto déficit calórico) se gasta menos por niño que en Lima. Pero este es un dato anecdótico. Ya pe causa! Estudios académicos no se basan en datos anecdóticos. Además si tú criticas que la política de Qali Warma está mal, debes demostrar que en su conjunto se está gastando menos dinero donde más se necesita. Pero lamentablemente los datos y estadísticas duras refutan tus conclusiones. En este punto en particular la política será desordenada, o sin ningún patrón o tendencia, pero no es lo que afirmas pe varón.
Ya otras personas han criticado este dichoso trabajo, @rmapalacios, la ministra Mónica Rubio, y Diario16.
El señor Pepe Botella, en un comentario a este post, me avisa que él ha encontrado otro ejemplo de uso y abuso de las estadísticas en el mentado reporte académico que la prensa usa para atacar a Qali Warma.
Quiero pensar que este ha sido un error de mal uso de estadísticas, aunque el asunto se vuelve un poco rochoso.
En la página 36 empieza un floro donde el autor manifiesta que Qali Warma gasta menos dinero en los más pobres («pobres multidimensionales»).
…la poca atención que reciben los pobres multidimensionales en términos de cobertura de servicios básicos genera una fuente de ineficacia en cuanto a la distribución del gasto público
La distribución departamental del gasto social está mal enfocada pues existen departamentos con un alto nivel de pobreza multidimensional que reciben un gasto social por debajo del promedio nacional
Osea la hipótesis es hay menor gasto en departamentos con mayor porcentaje de pobreza. Esto se debería demostrar con otra regresión lineal de ajuste significativo a la línea de tendencia. Y eso es lo que prentende hacer el autor al mostrar un gráfico muy colorido:

Regresión lineal con cuadrantes blancos y rosados. Qué hacen los cuadrantes allí?
Los datos están en la Tabla 4 del informe (página 37). Bajé los datos, hice el plot y calculé el coeficiente de determinación y el valor del p-value para ver si hay o no hay correlación entre las variables gasto y nivel de pobreza.

Gráfico sin los cuadrantes que estorban.
Y creo que ya te diste cuenta que NO hay relación entre las dos variables! Mira pé:
R2 = 0.02 (si hubiera correlación este debería ser cercano a 1)
p = 0.43 (si hubiera correlación este debería ser menor que 0.05)
El mismo error!
Pero aquí viene lo penoso. Qué michi hacen esos cuadrantes en tu gráfico? Primera vez en mi vida que los veo en un análisis de regresión. Los cuadrantes se usan en análisis canónico! ca-no-nico!
Si quieres demostrar algo categóricamente debes aplicar las estadísticas relevantes y que sean las más simples. Si quieres comparar 2 variables, haces regresión lineal (o ajustas una distribución exponencial, logarítmica, etc). Si quieres explicar el comportamiento de tus datos según múltiples variables haces un análisis de correspondencia canónico o similar.
No quiero pensar que estas tratanto de estirar los datos. Los desconfiados van a pensar que quieres estirar las estadísticas, forzándolas para que falsamente den soporte al resultado que quieres obtener. Debes tener cuidado chochera.
Sobre todo, causa desconfianza cuando, de todos los puntos de tu gráfico, escoges algunos, los que te conviene usar para criticar Qali Warma. Esos son datos anecdóticos. Otro broder podría escoger solo los puntos que dan una conclusión contraria y discutir ampliamente que Qali Warma hace un excelente gasto del dinero.
Para evitar esas subjetividades se hacen regresiones lineales, cálculos de coeficientes y tests de significancia (p-value). Cosa que tu informe aparenta hacer, pero no lo hace. Presentas tablas y gráficos pero haces cherry picking para la discusión! Además, ta que no he visto ninguna mención al R2 o al p-value en tu informe.
Sección geek
Aquí está los dos análisis estadísticos, el de ejemplo y el que rehice con los datos del informe del señor de la Universidad del Pacífico.
| require(stats) | |
| library(ggplot2) | |
| x <- read.csv("tabla31.csv", header=FALSE) | |
| plot(x$V3, x$V2, xlim=c(0,200), ylim=c(0, | |
| 70), | |
| ylab="Déficit calórico", | |
| xlab="Presupuesto de Gasto por niño (PIM)", | |
| main="Hay correlación entre gasto y déficit calórico?\nPrimicia: NO hay!") | |
| reg_lineal <- lm(x$V3 ~ x$V2) | |
| abline(lsfit(x$V3, x$V2)) | |
| summary(reg_lineal) | |
| # grafico de ejemplo | |
| sale5 <- c(13, 12, 12, 11, 12, 10, 7, 9, 8, 6) | |
| plot(sale5, main="Ejemplo de correlación lineal significativa", las=1) | |
| abline(lsfit(1:10,sale5)) | |
| summary(lm(1:10 ~ sale5)) | |
| # Tabla 4 | |
| x <- read.csv("tabla4.csv", header=FALSE) | |
| names(x) <- c("departamento", "porcentaje_pobres","gasto") | |
| plot(x$porcentaje_pobres, x$gasto, xlim=c(0,80), ylim=c(0,2100), | |
| main="\"A mayor pobreza hay menor gasto\":\nLos datos no te respaldan!", | |
| xlab="Tasa de pobreza multidimensional", | |
| ylab="Gasto social per capita", | |
| las=1) | |
| reg_lineal <- lm(x$porcentaje_pobres ~ x$gasto) | |
| abline(lsfit(x$porcentaje_pobres, x$gasto)) | |
| summary(reg_lineal) |
Aquí los datos originales usados en el reporte académico, tomado de su tabla 31.
| Amazonas,32.86,104 | |
| Áncash,32.65,134 | |
| Apurímac,50.49,139 | |
| Arequipa,38.41,118 | |
| Ayacucho,45.88,129 | |
| Cajamarca,53.93,120 | |
| Cusco,32.08,118 | |
| Huancavelica,35.60,125 | |
| Huánuco,42.40,125 | |
| Ica,20.06,152 | |
| Junín,39.74,154 | |
| La Libertad,37.90,110 | |
| Lambayeque,23.69,109 | |
| Lima,27.25,172 | |
| Loreto,37.05,143 | |
| Madre de Dios,15.36,148 | |
| Moquegua,25.64,141 | |
| Pasco,62.38,129 | |
| Piura,32.31,117 | |
| Puno,45.76,88 | |
| San Martín,22.30,128 | |
| Tacna,30.02,119 | |
| Tumbes,23.58,127 | |
| Ucayali,10.74,144 |
Aquí los datos originales de la tabla 4
| Moquegua | 24.8 | 1949 | |
|---|---|---|---|
| Tumbes | 28.4 | 1839 | |
| Ayacucho | 56.6 | 1779 | |
| Pasco | 55.8 | 1769 | |
| Huancavelica | 68.5 | 1750 | |
| Apurímac | 60.9 | 1725 | |
| Madre de Dios | 27.1 | 1584 | |
| Cusco | 38.2 | 1574 | |
| Amazonas | 61.7 | 1404 | |
| Tacna | 26.5 | 1399 | |
| Huánuco | 60.6 | 1361 | |
| Ancash | 43.4 | 1338 | |
| Ucayali | 42.6 | 1234 | |
| Puno | 55.3 | 1140 | |
| Loreto | 63.2 | 1118 | |
| Lima | 16.6 | 1093 | |
| Cajamarca | 67.8 | 1082 | |
| Ica | 16.6 | 979 | |
| San Martín | 51.1 | 966 | |
| Callao | 17.7 | 943 | |
| La Libertad | 41.6 | 906 | |
| Arequipa | 25.7 | 902 | |
| Junín | 40.1 | 889 | |
| Piura | 46.4 | 755 | |
| Lambayeque | 41.5 | 727 |
Parece que hay un troll en tuiter que me escribe cada vez que menciono los #narcoindultos. Este troll es aprista y le gusta alabar a los principales líderes del APRA (ya sea por tuiter, o comentando en artículos de la revista Caretas).
Como contestar a los trolls da un poco de flojera, decidí fabricar un bot que lo haga por mí. Este bot es un programa muy simple, escrito en Python, que responde a aquellos que deciden trolear mi cuenta de tuiter @AniversarioPeru.
Para esto modifiqué un muy simple chat-bot que encontré aquí: http://pythonism.wordpress.com/2010/04/18/a-simple-chatbot-in-python/.
Este bot necesita ser entrenado, osea hay que hacerlo «leer» unos cuantos libros para que sepa qué responder a los trolls.
Decidí hacer mi bot picaresco pero inteligente. Entonces le hice leer las Tradiciones Peruanas de don Ricardo Palma (se bajan el libro de aquí).
Podría hacer otro bot que tenga lenguaje un poco achorado. Para eso, su entrenamiento consistiría en hacerlo leer las columnas antiguas del malapalabrero.
En resumen, este bot busca si algún troll ha empezado a fastidiar por tuiter. Si esto es cierto, responderá al troll con frases sacadas de las Tradiciones Peruanas. Este bot es muy simple y las respuestas no tienen relación con lo que haya escrito el troll. Incluso, las respuestas no tienen mucho sentido. Supongo que será suficiente para que el troll se canse de fastidiar.
Lo bueno de tener un tuitbot es que interactuaría con los trolls mientras yo estoy durmiendo, en la discoteca o de vacaciones. El bot se activa cada media hora, pero si la cantidad de trolls aumenta, podría activarse cada 10 minutos.
Tengo planes de ir mejorando poco a poco este bot. Por ahora usa una aproximación a la cadena Márkov para construir su respuesta. Por ejemplo podría emplear estadísticas Bayesianas para entrenar el bot. Lo podría entrenar para que emita saludos, preguntas, afirmaciones, despedidas, insultos etc. El bot podría usar una aproximación bayesiana para darse cuenta si el troll ha emitido una pregunta, o un insulto y responder como amerite.
La ventaja de la inferencia Bayesiana es que al analizar las palabras de un tuit, puede ir aumentando o disminuyendo la probabilidad que el tuit sea —por ejemplo— saludo o insulto. Asumamos que un tuit tenga las palabras «caviar + rojo» hay probabilidad que el troll esté insultando. Si además el tuit contiene signos de interrogación repetidos, existe alta probabilidad que este tuit sea un insulto. Los estadísticos bayesianos llaman a esto último «probabilidad posterior».
Idealmente el bot analizaría cada tuit y decidiría qué responder si la probabilidad posterior indica que he sido insultado. Tendría que hacer que mi bot se entrene leyendo los tuits que le endilgan los trolls a @rmapalacios.
Aquí hay un ejemplo de cómo sería una interacción entre un troll y mi tuitbot actual (en rojo las respuestas del bot).
>ola k ase de Lima títere que el refrán: más allá esas calles. de su límite, de cucarachas. de la tía carnal; estas palabras: >Que triste tu vida esposa. de una vaca, de asiento, de la guitarra. de oro, de que le da colores--palabras que le sucede un tanto como hacemos >mermelada que defiendes!!! el reinado de la mazamorra, de grave en una mujer del rey. de nuestras abuelas eran una formidable invasión de plano. >arriba alianza! de la jerga franciscana. de la Monclova y el guardián del mando, de recibido varios de los jesuítas. >matemáticamente podemos clasificar al mundial de 1796 se plantaron en el Callao constituyó en su lado, de 1746, de aquel oportuno encarcelar, de una soberana paliza
Aqui les dejo el código completo del tuitbot. Requiere haber instalado un cliente de tuiter que se pueda usar desde una consola de comandos. En un post anterior detallé como usar el cliente llamado «t».
También requiere tener instalado Python. Y configurar el programa cron para que este tuitbot se active cada 30 minutos en búsqueda de tuits emitido por trolls (en este post explico como configurar cron).
Una vez que un troll es identificado, es necesario incluir el nombre de usuario en la lista de trolls para que el tuitbot sepa a quién dirigir su verbo florido.
Este es el programa que sirve para entrenar al bot. Se puede usar cualquier texto (de preferencia uno o más libros).
| import pickle | |
| import sys | |
| # Modified from http://pythonism.wordpress.com/2010/04/18/a-simple-chatbot-in-python/ | |
| b = open('tradiciones_peruanas.txt') | |
| text = [] | |
| for line in b: | |
| line = line.strip() | |
| for word in line.split(): | |
| text.append(word) | |
| b.close() | |
| textset = list(set(text)) | |
| follow={} | |
| for w in range(len(text)-1): | |
| check = text[w] | |
| next_word = text[w+1] | |
| print check | |
| print next_word | |
| if check[-1] not in '(),.?!': | |
| if follow.has_key(check): | |
| follow[check].append(next_word) | |
| else: | |
| follow[check] = [next_word] | |
| a = open('lexicon-luke','wb') | |
| pickle.dump(follow,a,2) | |
| a.close() |
Este es el programa que se encarga de recibir un mensaje y responder.
| import pickle | |
| import random | |
| import sys | |
| import re | |
| # Modified from http://pythonism.wordpress.com/2010/04/18/a-simple-chatbot-in-python/ | |
| a = open('lexicon-luke','rb') | |
| successorlist = pickle.load(a) | |
| a.close() | |
| avoid = ["a", "en", "el", "que", "la", "del", "esta", "de", "su", "con"] | |
| def nextword(a): | |
| if a in successorlist: | |
| try: | |
| return random.choice(successorlist[a]) | |
| except: | |
| return '' | |
| else: | |
| return 'de' | |
| def get_response(input): | |
| response = '' | |
| s = random.choice(input.split()) | |
| while True: | |
| neword = nextword(s) | |
| if neword != '': | |
| response += neword + ' ' | |
| s = neword | |
| if len(response) > 120: | |
| for i in avoid: | |
| regex = re.compile('\s%s\s*$'%i, re.I) | |
| if regex.search(response): | |
| response = regex.sub("", response).strip() | |
| break | |
| return response.strip() | |
| if __name__ == "__main__": | |
| speech = '' | |
| while speech != 'quit': | |
| speech = raw_input('>') | |
| response = get_response(speech) | |
| print response |
Este es el tuitbot que se encarga de leer lo que emiten los trolls y responderles via tuiter.
| #!/usr/bin/env python | |
| # -*- coding: UTF8 -*- | |
| import codecs; | |
| import os; | |
| import datetime; | |
| import re; | |
| import bitly; | |
| import subprocess; | |
| import time; | |
| import sys; | |
| from random import choice; | |
| import lukebot | |
| debug = 0; | |
| saved_tuits_file = "/data/projects/aniversario_peru/saved_tuits.txt" | |
| # t update "mi primer tuit" | |
| cmd2 = '/usr/local/bin/t set active AniversarioPeru' | |
| p = subprocess.check_call(cmd2, shell=True); | |
| def get_last_tuit(user): | |
| if debug: | |
| cmd = "cat debug_tuits.txt | grep -i " + user + " | head -n 1" | |
| p = subprocess.check_output(cmd, shell=True); | |
| else: | |
| cmd = "/usr/local/bin/t mentions -l -c | grep -i " + user + " | head -n 1" | |
| p = subprocess.check_output(cmd, shell=True); | |
| if len(p) > 0: | |
| p_ = p.split(",") | |
| tuit_id = p_[0] | |
| tuit_date = p_[1] | |
| message = p.split(',"')[1] | |
| message = message.replace('"', '') | |
| message = re.sub("\s*@AniversarioPeru\s*", "", message, re.I) | |
| return { | |
| "tuit_id": tuit_id, | |
| "tuit_date": tuit_date, | |
| "user": user, | |
| "message": message | |
| } | |
| return "none" | |
| def is_new_tuit(tuit): | |
| # file full of tuits | |
| f = open(saved_tuits_file, "r") | |
| file = f.readlines(); | |
| f.close() | |
| is_new_tuit = "true" | |
| for line in file: | |
| line = line.strip() | |
| line = line.split(",") | |
| print line | |
| if line[0] == tuit['tuit_id'] and line[2] == tuit['user']: | |
| is_new_tuit = "false" | |
| return is_new_tuit | |
| def get_message(frases_to_reply): | |
| return choice(frases_to_reply) | |
| def reply(tuit): | |
| #message = get_message(frases_to_reply) | |
| message = lukebot.get_response(tuit['message']) | |
| cmd = "/usr/local/bin/t reply " + tuit['tuit_id'] + " '" + message + "'" | |
| p = subprocess.check_call(cmd, shell=True); | |
| users = [ | |
| "addTrollUser" | |
| ] | |
| for user in users: | |
| tuit = get_last_tuit(user) | |
| if tuit != "none": | |
| # is the last tuit a new one? | |
| if is_new_tuit(tuit) == "true": | |
| reply(tuit) | |
| # save tuit | |
| f = open(saved_tuits_file, "a") | |
| f.write(tuit['tuit_id'] + "," + tuit['tuit_date'] + "," + tuit['user'] + "\n") | |
| f.close() | |
| else: | |
| print "we replied already" |
Según Wikipedia, un hacker es:
«A person who enjoys exploring the details of programmable systems and stretching their capabilities, as opposed to most users, who prefer to learn only the minimum necessary.»
Algunos creen equivocadamente que hacker = malechor, delincuente. Pero lo cierto es que hay varios tipos de hackers.
Además individuos considerados como hackers de la subcultura de programadores pueden hacer tareas repititivas de 100 a 1,000 veces más rapido que usuarios que no son hackers (gracias a que usan de técnicas de computación avanzadas).
El congreso peruano ha aprobado una ley de delitos informáticos recontra ridícula que ha sido criticada por muchos, por ejemplo en el blog http://iriartelaw.com y http://www.hiperderecho.org, además de ser considerada una ley Frankenstein. Esto evidencia que el congreso legisla sobre temas que desconoce.
Para demostrar qué tan mal redactada está la ley ex-beingolea. He decidido hackear las páginas web del Congreso de la República. Y aquí detallo el procedimiento.
Quiero hacer uso de programas informáticos para averiguar cúantos proyectos de ley ha propuesto cada congresista durante este año 2013.
Hay que buscar la página web del congreso que tiene la lista de los proyectos de ley emitidos este año:

Buscar la página con los proyectos de ley.

Listado de proyectos de ley por fecha.
Si vemos el código original HTML de esa página (hacer CTRL-U, si están en Mozilla Firefox) veremos que está compuesta de 4 «frames». Cada «frame» corresponde a una parte de la página. Me interesa el último «frame», el que contiene la lista de links a los proyectos de ley.

Código HTML de la página del congreso
Si hacemos click al último «frame» nos encontramos con esta página:

«Frame» conteniendo la lista de proyectos de ley.
Esta página lista 100 proyectos de ley, y al ver la dirección URL de esta página, nos damos cuenta que basta con cambiar el último parámetro Start=1 por Start=100 para obtener los siguientes 100 proyectos de ley.
Osea cambiar:
http://www2.congreso.gob.pe/Sicr/TraDocEstProc/CLProLey2011.nsf/PAporNumeroInverso?OpenView&Start=1
por:
Puedo escribir un hack (osea script) que me colecte rápidamente todas las páginas que contienen los links. En lugar de bajarme documento por documento (lo cual me tomaría muuuuucho tiempo), lo puedo hacer al toque si hago uso de las tecnologías de información y comunicación que tanto miedo causa a los congresistas:
| #!/bin/bash | |
| for i in {0..900..100} | |
| do | |
| if [ $i = 0 ]; then | |
| torsocks wget "http://www2.congreso.gob.pe/Sicr/TraDocEstProc/CLProLey2011.nsf/PAporNumeroInverso?OpenView" | |
| else | |
| torsocks wget "http://www2.congreso.gob.pe/Sicr/TraDocEstProc/CLProLey2011.nsf/PAporNumeroInverso?OpenView&Start=$i" | |
| fi | |
| done |
Hay 812 proyectos de ley para examinar. Necesitamos descargar cada proyecto de ley y copiar la lista de autores para contar cuántos proyectos ha sido emitido por cada congresista. Obviamente hacer esto manualmente me demoraría una eternidad. Para eso he creado un segundo hack. Es un script in Python que examina cada link, y extrae los nombres de los congresistas que son autores de cada proyecto de ley. Junta todos los nombres y hace un gráfico para poder visualizar los datos (el código de programación está al final de este post).
Bueno, el script estaba demorando mucho, me cansé de esperar y cancelé el programa por lo que no pude colectar toda la info. Pero la idea se entiende no?

Número de proyectos de ley presentado por cada congresista durante el 2013
Aquí se pueden descargar la dichosa ley http://www.hiperderecho.org/wp-content/uploads/2013/09/nuevaleybeingolea.pdf.
Hagamos recuento de las veces que he faltado a la ley:
El que, a través de las tecnologias de la información o de la comunicación, introduce,
borra, deteriora, altera, suprime o hace inaccesibles datos informáticos, será reprimido
con pena privativa de libertad
-> Al escribir este post he introducido datos informáticos al servidor de WordPress usando tecnologías de la comunicación.
El que, crea, ingresa, o utiliza indebidamente una base de datos sobre una persona natural o jurídica, identificada o identificable, para comercializar; traficar, vender, promover, favorecer o facilitar información relativa a cualquier ámbito de la esfera personal, familiar, patrimonial, laboral, financiera u otro de naturaleza análoga, creando o no perjuicio, será reprimido con pena privativa de libertad no menor de tres ni mayor de cincó años.
-> Al bajarme la lista de proyectos de Ley del Congreso he ingresado a su base de datos para facilitar la información relativa al ámbito laboral de cada congresista sin crear perjuicio (ojo que no es necesario causar perjuicio para ir en contra de la ley).
El que fabrica, diseña, desarrolla, vende, facilita, distribuye, importa u obtiene para su utilización, uno o más mecanismos, programas informáticos, dispositivos, contraseñas, códigos de acceso o cualquier otro dato informático, específicamente diseñados para la comisión de los delitos previstos en la presente Ley, o el que ofrece o presta servicio que contribuya a ese propósito, será reprimido con pena privativa de libertad no menor de uno
ni mayor de cuatro años y con treinta a noventa días-multa.
-> En este post publico el programa informático que he fabricado, diseñado y desarrollado con el fin de específicamente incumplir los artículos 3 y 6 de la presente Ley.
Señores congresistas métanme preso. Quiero cárcel dorada como Antauro y Fujimori. Gracias.
Aqui está el código para bajarse los nombres de los congresistas que fueron autores de proyectos de ley durante el 2013:
| #!/usr/bin/env python | |
| # -*- coding: utf-8 -*- | |
| import socks | |
| import cookielib | |
| import socket | |
| from bs4 import BeautifulSoup | |
| import requests | |
| import sys | |
| import re | |
| from os import listdir | |
| import codecs | |
| import urllib2 | |
| socks.setdefaultproxy(socks.PROXY_TYPE_SOCKS5, "127.0.0.1", 9050) | |
| socket.socket = socks.socksocket | |
| def extract_doc_links(soup): | |
| our_links = [] | |
| for link in soup.find_all("a"): | |
| if re.search("201[0-9]-CR$", link.get_text()): | |
| href = link.get("href") | |
| if href.endswith("ocument"): | |
| our_link = "http://www2.congreso.gob.pe" + "/" + href | |
| our_link = re.sub("//Sicr","/Sirc", our_link) | |
| our_links.append(our_link) | |
| return our_links | |
| def parse_names(string): | |
| """ | |
| Parse string of names. Output only family name as list. | |
| """ | |
| names = [] | |
| for i in string.split(","): | |
| i = re.sub("\s{2}.+", "", i) | |
| names.append(i) | |
| return names | |
| def get_authors_from_project(document_link): | |
| """ | |
| input: link to project page | |
| output: list of author names as list | |
| Using tor, found help here: | |
| http://stackoverflow.com/questions/10967631/how-to-make-http-request-through-a-tor-socks-proxy-using-python | |
| """ | |
| cj = cookielib.CookieJar() | |
| opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj)) | |
| opener.addheaders = [('Accept-Charset', 'utf-8')] | |
| request = urllib2.Request(document_link) | |
| request.add_header('Cache-Control','max-age=0') | |
| response = opener.open(request) | |
| proyecto = BeautifulSoup(response.read().decode("utf-8")) | |
| del request | |
| del response | |
| for i in proyecto.find_all("input"): | |
| if i.get("name") == "NomCongre": | |
| return parse_names(i.get("value")) | |
| ## ———————————————— | |
| def main(): | |
| all_links = [] | |
| for file in listdir("."): | |
| if file.startswith("PA"): | |
| print file | |
| f = open(file, "r") | |
| html_doc = f.read() | |
| f.close() | |
| soup = BeautifulSoup(html_doc) | |
| all_links += extract_doc_links(soup) | |
| print "Numero de proyectos de ley: %i " % len(all_links) | |
| # Save names to file | |
| f = codecs.open("all_authors.csv", "w", "utf-8") | |
| f.write("Congresista\n") | |
| f.close() | |
| f = codecs.open("all_authors.csv", "a", "utf-8") | |
| for link in all_links: | |
| authors = get_authors_from_project(link) | |
| for author in authors: | |
| f.write(author + "\n") | |
| f.close() | |
| if __name__ == "__main__": | |
| main() |
Y aquí el código para plotear los datos:
| # -*- coding: utf-8 -*- | |
| import codecs | |
| import prettyplotlib as ppl | |
| import numpy as np | |
| from prettyplotlib import plt | |
| import csv | |
| x = [] | |
| y = [] | |
| with open("all_authors.csv_bak", "rb") as csvfile: | |
| f = csv.reader(csvfile, delimiter=",") | |
| for row in f: | |
| x.append(row[1].decode("utf-8")) | |
| y.append(row[0]) | |
| y = map(int, y) | |
| plt.rc('font', **{'family': 'DejaVu Sans'}) | |
| fig, ax = plt.subplots(1, figsize=(20,6)) | |
| width = 0.35 | |
| ind = np.arange(len(y)) | |
| xdata = ind + 0.05 + width | |
| ax.bar(ind, y) | |
| ax.set_xticks(ind + 0.5) | |
| ax.set_xticklabels(x, rotation="vertical") | |
| ax.autoscale() | |
| ax.set_title(u'Ranking de proyectos de ley por congresista', | |
| fontdict = {'fontsize':24} | |
| ) | |
| plt.ylabel(u'Número de proyectos de ley', fontdict={'fontsize':18}) | |
| plt.xlabel(u'Congresista', fontdict={'fontsize':22}) | |
| ppl.bar(ax, np.arange(len(y)), y, grid="y") | |
| fig.tight_layout() | |
| fig.savefig("ranking_congresista.png") |



